 Erik航行适用于Sandia的先进设备技术部门。他是一名成员半导体国际技术路线图自2005年以来。
Erik航行适用于Sandia的先进设备技术部门。他是一名成员半导体国际技术路线图自2005年以来。
DeBenedictis获得加州理工学院计算机科学博士学位。作为一名研究生和博士后,他研究的硬件变成了第一个超立方体多处理器计算机。后来被称为“宇宙立方体当他离开大学后,它跑了十多年,并一遍又一遍地复制。它被认为是今天大多数超级计算机的祖先。
在20世纪80年代,在霍蒙德的霍尔莫德尔贝尔实验室工作,黛芬德是一个联盟的一部分,竞争第一个Gordon Bell奖。该团队获得了第二个地方奖,第一个去桑迪亚的地方。在20世纪90年代,他在公司开发了桌面和无线系统的信息管理软件的公司中运行Netalive。金宝博官方从2002年开始,Debenedictis是其中一个项目领导着红风暴超级计算机。
Erik表达的意见下面是他自己而不是桑迪亚或美国能源部的意见。本文件已被桑迪亚发布为2014-2679P的沙子。
路加福音Muehlhauser如你的一些工作涉及到可逆计算,我以前就是这样做的讨论了与迈克弗兰克。迈克的观点似乎是有希望的迹象表明可逆计算最终可能是可能的,但由于缺乏资金和感兴趣的研究人员,进展不会迅速移动。金宝博娱乐是你的看法吗?并根据我对他的采访,你似乎有一个大幅迈克对我和他讨论过的事情有不同的看法?
Erik航行我同意Mike的观点,但是他关于计算中不可逆性的最小能量的讨论只是从“摩尔终止定律”开始的计算中最小能量的更大话题的一部分。
对于没有阅读Mike Frank的采访的任何读者,我想快速摘要相关点。迈克接受了关于可逆逻辑的采访,有时被称为可逆计算。如果您是一名辉煌的工程师,并且可以弄清楚如何制作计算机逻辑门,或者每个逻辑操作(KT的含义在下一段中的含义),您可以发现额外的热量生产根据信息和热力学之间的相互作用,根据KT的顺序。如果您决定甚至更低的电脑盖茨,您必须使用可逆的逻辑原则。您可以使用不同的通用门集,其中包括新门,例如Toffoli或Fredkin门。您也可以使用常规栅栏(例如,或,或,不是)和“撤回级联”时钟方案,该方案捕获答案后逆转计算。
kT参考:k = 1.38 × 10-23年Joules / Kelvin是Boltzmann的常数,T是T = 300个keelvin的绝对温度在室温下。Kt大约4个Zeptojoules = 4 x 10-21年焦耳。将这个数字与今天的计算机进行比较是不精确的,因为今天计算机的耗散主要是由长度不同的互连线引起的。现代计算机中的“与”或“与”门可能消耗这个值的一百万倍。
许多受人尊敬的科学家认为可逆计算是可行的,但具有挑战性。如果他们的观点是正确的,计算应该在“任意低能级”上是可能的,所有提出不可避免的一般极限的理论都是不正确的。有一些相反的理论提出了用于计算的最小能量耗散水平。其中几个关键问题是每个逻辑运算“在kT阶上”的朗道极限1, a thermal limit of 40-100 kT (depending on your definition of reliable), and the concept in the popular press today that “Moore’s Law is Ending” and the minimum energy per computation is whatever is in the rightmost column of the International Technology Roadmap for Semiconductors (ITRS). That value is about 50,000 kT with typical lengths of interconnect wire.
有多种相互竞争的理论的科学情况可以通过科学实验来解决。例如,纽约的一位研究人员有一个亚kt范围的超导电金宝博娱乐路,看起来可以在他的芯片的另一对“旋转”中演示逻辑电路。证明和严格测量一个次kt电路将使目前所有声称不可避免的极限的理论失效。
是否有任何人会资助这样的实验应该取决于任何人是否关心结果,我想提出两个社会层面的问题,即实验将解决:
计算机产业在第二次世界大战期间开始上升趋势,工业收入和计算机吞吐量在持续70年的相当清晰的指数增长。目前半导体和下游产业的年收入约为7万亿美元。如果计算有一个更低的能量极限,增长率的变化将导致世界经济的一个小故障。我的观点是,证明或否定计算极限理论每年只需花费7万亿美元的一小部分。
第二个与深刻重要的计算问题有关,例如仿真全球环境,以评估气候变化问题。在Petaflops超级计算机上运行的现有气候模型为未来的气候提供不同的预测,这些预测在过去十年中的观测中发散。无论政治如何,补救措施都是一个更复杂的气候模型,在更大的超级计算机上运行。我们不知道这方面有多较大,但在这种背景下已经提到了Zettaflops或更多。如果任何最小能量耗散理论是正确的,所需超级计算机的能量耗散可能会变得过大,气候建模可能是不可行的;如果在“任意低级”在“任意低级”可能的理论是真的,则准确的气候建模只需要高级计算机。
我试图扩大迈克的观点:可逆计算的研究可以阐明经济的未来和地球的气候,但我不知金宝博娱乐道为可逆计算研究资助的单身人士。此外,可逆计算的确凿证明将表明有足够的空间来提高计算机效率并因此的性能。如果“Moore的法律结束”是指以提高计算机效率的结束,验证可逆计算会显示这是一个选择的问题而不是技术。
卢基:从您的角度来看,目前可以预见的摩尔定律可能遇到的主要障碍是什么之前达到朗道极限?(这里,我想的更多的是经济上的重要性”每美元计算“摩尔定法的配方而不是”串行速度“制剂,其2004年碰壁.)
伊利克:有巨大的上行,但不一定适用于每个应用程序。The “computations per dollar” link in the question focused on the use of computers as a platform for strong Artificial Intelligence (AI), so I will comment specifically on that application: I wouldn’t be surprised to see AI accelerated by technology specifically for learning, like neural networks with specialized devices for the equivalent of synapses.
让我们考虑(a) 1965年的摩尔定律是2020年,(b)超越摩尔定律2020年+。
从1965年到2020年,策略是缩小线宽。这个策略对10个人是有效的12或者说每一美元的计算量增加了。
我认为,2020年以后的以下几类技术进步,每一类都可能带来10-100倍的效率提高:
- 更有效的von Neumann架构的实现。
- 更多的并行性,随着编程难度的相应增加。
- 提高软件执行效率(例如,使用新的计算机语言和编译器在图形处理单元上运行通用代码)。
- 用较少的计算解决给定问题的更好的算法。
- 如今CPU + GPU等加速器可扩展到CPU + GPU +各种新的加速器类型。
- 即使在每个门运行的能量不变的情况下,继续在2D中缩放,更好地利用第三维来减少通信能量。
- 光学互连具有上行状态,但光学频率通常超卖。
- 纳米器件的性能不同于晶体管,它能让一些计算机功能更有效地完成。例子:忆阻器,模拟元件。
- 通过绝热方法、亚阈值或低阈值操作或概率计算改进了门技术。最终,可逆计算(请注意下面这一点)。
- 不使用通常定义的门的可选计算模型(如神经形态)。
如果上面列出的10个项目每一美元的计算量平均增加1.5个数量级,你就比摩尔定律的整个运行有更多的上行空间。
如果列表中的一些项目没有成功,你可以通过集中精力在其他路径上获得优秀的结果。因此,我认为短期内不会出现普遍的技术崩溃。然而,某些特定的应用程序可能只依赖于上述列表中的一个子集(前面提到了气候建模),可能容易受到限制。
可逆计算加上每台设备制造成本的持续降低可能会极大地扩大上行潜力。
但是,为了一个不太明确的目的,未来必要的技术投资将会更大。摩尔定律传达的信息非常简洁:工业和政府投资于线宽的收缩,并获得了巨大的回报。未来将需要许多技术投资,它们的目的不那么明确。
底线:总的来说,前面的道路是昂贵的,但是每一美元的计算量会大幅增加。特定的应用程序类可能会有限制,但是必须对它们进行具体分析。
卢基你认为在未来的15年里,中国是否会黑硅的问题会威胁到摩尔定律(每美元计算数)吗?
伊利克我相信黑硅问题会对每美元的计算量产生负面影响。这个问题和潜在的能源效率问题将会变得更糟,至少在增加能源的成本大于提炼解决方案并将其投入生产的成本之前。这种情况最终会发生,但我相信,这个问题持续的时间会比预期的要长。然而,当你承认存在暗硅问题时,你就承认摩尔定律已经结束了。
暗硅的潜在原因是技术比降低功率更快地缩放设备尺寸。This causes power per unit chip area to increase, which contradicts the key statement in Gordon Moore’s 1965 paper that defined Moore’s Law: “In fact, shrinking dimensions on an integrated structure makes it possible to operate the structure at higher speed for the same power per unit area.”
不匹配的缩放速率为每美元计算创建问题。今天,购买计算机的成本大致等于将电力提供电力的成本。除非可以增加功率效率,否则对计算机逻辑的改进不会受益于用户,因为他们使用的计算量将受到电力账单的限制。
不匹配的缩放率可以通过关闭晶体管(黑硅)、封装具有低能量密度功能的微处理器如内存(在某种程度上,这是个好主意)和专业化(在下面的采访中描述)来解决(但没有解决)黑硅的问题)。
可以通过更多的功率有效的晶体管(例如隧道场效应晶体管(TFET))一起聚集缩放速率。但是,这种晶体管类型仅持续几代。看这里.
理论说每个计算的能量可以“任意小”,但研发利用这些问题将是昂贵和破坏性的。我知道的主要方法是:
绝热.一种完全不同的逻辑门电路方法。例子:迈克·弗兰克的2LAL。
某些低压逻辑类:例如,参见arXiv 1302.0244中的CMOS LP(与ITRS CMOS LP不同)。
可逆计算,主题迈克弗兰克的采访.
上述方法是可破坏性的,我相信今天限制了他们的受欢迎程度。该方法使用CMOS的不同电路,这将需要新的设计工具。开发的新设计工具将昂贵,并且需要重新培训使用它们的工程师。孩子们学习“和”和“或”当他们大约一岁的时候,这些话成为计算机的普遍逻辑基础的基础。要利用一些节省计算机权力的技术,您必须根据Toffoli,CNOT等不同的逻辑基础思考。上面的一些想法将要求人们放弃他们被吸引的概念,以便在之前没有理由询问。
卢基:你的意思是什么,“当你承认有一个黑暗的硅问题时,你已经结束了什么”?计算每年摩尔的法律至少在2011年初举行(我尚未在此之后检查数据),但我们从2010年或更早之前了解了黑暗的硅问题。
伊利克:摩尔的法律随着时间的推移多么含义,也是更大活动的一部分。
有一个非常有趣的诺霍斯研究它揭示了大型计算机的峰值计算速度在二战前后经历了一个拐点,并且从那以后一直呈指数增长。根据他论文的图表2,我认为这种指数趋势始于1935年。
Gordon Moore于1965年发表了一篇论文,标题为“在集成电路中塞入更多的元件“这包括每芯片的组件图与年份。正如我所提到的先前问题所示,本文的文本包括句子,“实际上,集成结构上的尺寸收缩尺寸使得可以以每单位面积的相同功率更高的速度操作该结构。”图表和前一句话似乎是1974年Dennard正式的潜在扩展规则的主观描述,称为Dennard缩放。
I have sketched below Moore’s graph of components as a function of year with Nordhaus’ speed as a function of year on the same axes (a reader should be able to obtain the original documents from the links above, which are more compelling than my sketch). This exercise reveals two things: (1) the one-year doubling period in Moore’s paper was too fast, and is now known to be about 18 months, and (2) that Moore’s Law is a subtrend of the growth in computers documented by Nordhaus.
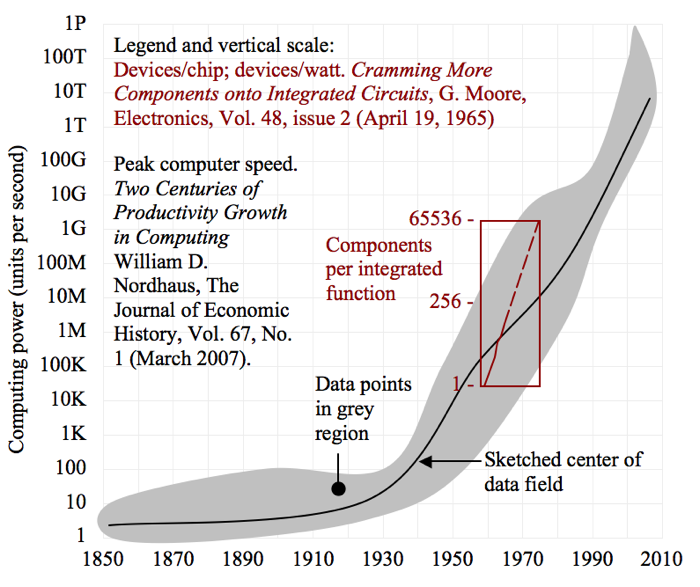
一个非常有趣的问题是,摩尔是在应用别人的定律,还是说这两个定律实际上是一个更大的概念的一部分,而这个概念当时还没有被理解。我的结论是后者。直到摩尔的文章发表6年后,英特尔才发明了微处理器。我还和一些人(不是摩尔)谈过,他们告诉我戈登·摩尔考虑的是通用电路,没有预见到微处理器的出现。
让我试着用他的论文定义摩尔的法律。我记得1981年建立计算机系统,8086(与原始IBM P金宝博官方C中的8088非常相似)。我听说它非常复杂,消散了很多热量,所以我把手指放在它上面来体验热量。我记得惊讶的是,它看起来不像其他任何东西。33年后,我对去年微处理器的热量有所了解。由于Moore的法律说每单位面积的电源是相同的,芯片几乎与1厘米的大小相同2,我应该能够把手指放在芯片上,感觉不热。现实是,坐在今天的微处理器之上有一个新的结构,让我想起了Darth Vader的头部,并被称为“散热器”。散热器是去除由芯片产生的50-200瓦的热量。我相信我刚刚做出了一个带有散热器的微处理器违反了摩尔定律的案例。
这是怎么呢摩尔定律被赋予了比摩尔所想的更多的意义。许多人认为摩尔定律只是关于维度缩放的,他的文章标题和主要图表支持了这一结论。摩尔定律也与每美元的计算有关,但在摩尔的论文发表之前,这个定律已经存在了30年。
我发现了面试随着哈迪Esmaeilzadeh在黑暗的硅上追踪,但他使用了对摩尔定律的另一种解释 - 摩尔法继续存在的解释,但丹尼德缩放在2000年代中期结束。然而,我引用了摩尔论文的短语,披露了后来被称为丹尼德缩放的缩放规则。
在更高的级别,我认为Moore的法律已成为半导体行业所需的营销短语,因此它仍然是正确的。
那么为什么每美元的计算升起?多年来,供应商目标是使处理器更快地运行Word处理器和Web浏览器。这一趋势在2000年代初期的趋势中有效,处理器等处理器,具有4 GHz时钟并耗散200W +。顾客反叛和行业转移到多夜。通过N核微处理器,在一个核心上运行基准的结果可以乘以n。这是第2项在我对先前问题(更平行的难以进行编程时)的响应中的进展(每美元计算计算)的示例。即使是现在,大多数软件也没有利用多个核心。
卢基你写道:“客户开始反抗,行业转向多核。”我通常听到一个不同的故事,2002 - 2006年的时代,一个没有与客户反叛,而是由行业实现最快的方法保持Moorean趋势——消费者和制造商已经成为习惯是跳转到多核。这就是我在例句中看到的故事。计算性能的未来由国家院校出版社(官方摘要这里)。此外,对摩尔定律的权力缩放挑战预计了业界的多年,例如在ITRS报告中.你能解释一下你所说的“顾客反抗”是什么意思吗?
伊利克:如果你对未来的预测是正确的,然后预测发生了变化,会发生什么?你最终会发现历史记录中关于同一件事的多个“真相”。我承认你听到的故事是真的,但基于不同的预测,还有另一个事实。
让我们从数学上颠倒ITRS路线图,看看当今(2014)微处理器时钟速率的预测是如何随着工业解决功率扩展和转向多核的问题而演变的。我已经回去了早期的ITRS版本以及2003年、2005年和2007年的访问版报告。在每个版本的执行摘要的表4中,他们有一个“芯片本地时钟”的投影,这意味着微处理器时钟速率。我访问Pricewatch获得2014时钟速率。
| 芯片本地时钟 | 2013年 | 2014年 | 2015年 |
| 2003年ITRS的预测 | 22.9 GHzTable 4摄氏度 | 这一版只报道了奇数年 | 33.4 GHZTABLE 4D |
| 2005年ITRS的投影 | 28.4 GHZTABLE 4D | ||
| 2007年ITRS的预测 | 7.91 GHzTable 4摄氏度 | ||
| 2014年的现实 | 4.0 GHz pricewatch.com. |
最显着的问题是,2003年和2005年版本夸大了钟速约7倍。ITRS在2007年收纳到多芯,并以新的缩放模型在回想表中看到了仅2倍的现实。2007年ITRS中的脚注1描述了变化。脚注以下列句子结束:“这是反映最近的片上频率速度速度和预期的速度 - 电源设计权衡,以管理最多200瓦/芯片经济实惠的电源管理权衡。”
如果您相信ITRS是“工业”,那么工业已经告诉客户通过提高时钟速率来期待摩尔定律的好处。在我看来,客户带头说,每个芯片的功率应该低于200瓦,即使这意味着更难使用并行编程模型。在多核技术流行的几年后,行业改变了它的预测,因此客户期望通过提高每一美元的计算量而不是速度来获得进步的好处。当然,这导致了电池驱动的智能手机和限电远低于200瓦的平板电脑的兴起。
顺便说一句,我以前从没听过“摩尔风”这个词。它似乎抓住了计算机技术进步的概念,而不与特定的技术属性挂钩。为什么不注册商标?它得到0个谷歌。
卢基您愿意对未来15年的计算机行业做一些预测吗?对于以下任何一种情况,我都很想知道你的估计点,或者更好的是你的70%置信区间:
- 到2030年,顶级超级计算每美元的失败数字。
- 到2030年,高端超级计算中每个活动逻辑门的平均kT值。
- 在2030年,可逆计算的一些特殊程度的进展情况?
- 2030年世界FLOPS的总容量。(见这里.)
或者说,任何关于2030年计算的具体预测。
伊利克:每一美元的问题将是最有趣的,所以我把它留到最后。
kT /逻辑运算我认为在1万kT左右会出现一个平台期,在下一段中我会讨论这个平台期之后会发生什么。我猜10000 kT包括互连线,这是很重要的,因为今天75-90%的能源可归因于互连线。今天,我们看到大约5万kT。将电源电压降低到0.3 v应该可以提高10倍,但还有其他问题。这个估计在10年内应该是有效的,但是问题问的是大约15年。
我不会感到惊讶,我们在间隔2025-2030中看到了一种新的方法(如下所述)。将特别难以预测,但五年间隔短,并且提高率似乎对细节不敏感。因此,据说2030年有5倍的额外改进。
累积到2030年: 2000 kT/逻辑运算,包括互连线。然而,这将真的令人失望。根据摩尔定律,在15年的时间间隔内,人们预计会有10倍的增长,预期会有1024倍的提高;我预测25 x。
可逆计算我认为可逆计算(严格定义)将在几年内被证明,并主要影响社会的思维过程。这个演示将是计算在低于1 kT/逻辑运算,理论上说,除非使用可逆的计算原理,否则这些水平是无法实现的。我不认为可逆计算能在2030年前得到广泛应用。2030年2000 kT/逻辑作业的预测代表了制造成本和能源成本的平衡。
到2030年,可逆计算可能会应用于一些电力非常昂贵的领域,比如宇宙飞船或可植入医疗设备。
然而,可逆计算的演示可能会对社会思维产生重要影响。流行思想认为某些想法对于规划来说是无限的,并赋予这些想法关注和投资。这适用于加州的房地产价格(直到2008年)和摩尔定律(直到几年前)。“摩尔定律即将终结”的说法将计算带入了第二种被普遍认为是有限的思想,比如铁路的未来增长潜力。一个可逆的计算演示将把计算移回第一类,从而使更多的注意力和资金可用。
然而,可逆计算是连续体的一部分。我看到绝热方法可能成为上述2020-2025时间范围的新方法。
全球总拖波能力,2030年.我看了一下Naik文档你引用。我觉得没有资格评判他的成绩。然而,我将坚持我的比例50000 kT和2000 kT = 25。所以我的答案是用奈克的结果乘以25。我不认为电脑的累积耗电量会大幅增加,特别是在采取绿色措施后。
失败/美元:这个答案将到处都是。让我们通过应用程序类分解:
(a)一些应用程序是CPU绑定的,这意味着它们的性能将跟踪每个逻辑OP的KT中的变化。我猜猜我猜测了25倍的改进(这少于摩尔法的1024倍,那么摩尔定律将会交付)。
(b)其他应用程序是内存绑定,意味着它们的性能将跟踪(a)内存子系统性能,其中由于摩尔定律和(b)可以减少数据移动量的架构更改,所以在造成的架构中部分重叠。金宝博官方
使计算机(a)比(b)更容易更容易;对于给定的成本,与B型相比,计算机将在拖鞋上以幅度或更多级别呈现型应用程序。
顶端超级计算机支持A和B,但A和B之间的平衡可能是时代的深刻问题。平衡已经大量加权,支持(通过依赖Linpack作为基准)。但是,我们目前没有在美国拥有特别侵略性的Exascale计划。相反,我们有很多关于内存子系统的低能量效率的讨论。金宝博官方您可以对最终超级计算机的进展进行相当引人注目的案例,直到计算机变得更好地平衡。
(对于参考,前2个超级计算机是ornl泰坦,17.5 petaflops Linpack为9700万美元;比例为181 MFLOPS / $。前1个超级计算机似乎并不良好的成本参考。)
如果架构保持固定到2030,我会猜测25倍的改进。这将是4.5 gflops / $。存储器子系统由与逻辑金宝博官方相同的晶体管技术制成,也许加上越来越多的光学元件。如果晶体管通过25倍变得更有效,则这可以使拖鞋和存储器子系统受益。金宝博官方使用3D可以提高性能(由于电线较短),但由于难以利用更大的并行性,这将抵消效率损失。打电话给后一种因素洗净。
架构是通配符。有一些已知的架构比冯·诺伊曼机效率高得多,比如收缩阵列、内存处理器(PIM)、现场可编程门阵列(fpga)甚至gpu。这些体系结构通过组织自身使计算更接近存储数据的位置,从而使完成任务所需的时间和精力更少,从而提高了性能。不幸的是,这些架构的成功是以一般性为代价的。如果供应商通过过多的专门化来提高性能,那么作为“高端超级计算机”的一个例子,他们就有被取消资格的风险。圣杯将是一种软件方法,它将使通用软件在一些专门的硬件上运行(比如编译器将在GPU上运行通用的C代码-以GPU的全部性能)。
但是,我将预测架构改进将额外的4X到2030,累积提高因子100倍。这将是18 GFLOPS / $。这仍然是1024倍的10倍,预计15年。
然而,我认为由于专业化,人工通用智能(AGI)可能会发展得很好。突触活动是生物能够思考的主要功能,但它与超级计算机中的浮点数有很大不同。突触基于模拟刺激和模拟学习行为执行局部、缓慢的计算。相比之下,超级计算机中的浮点运算速度非常快,可以从遥远的内存中获取数据,并以64位的精度计算出答案。速度会降低能源效率,超级计算机甚至不会学习。由于冯·诺伊曼计算机是图灵完备的,它将能够执行软件编码的AGI。但是,效率可能较低。
执行AGI可以通过新的或专门的技术进行优化,并比摩尔定律的速度更快,比如比特币挖矿。我计划大规模的AGI演示将需要非常规的,但不是不可想象的计算机。计算机可以是专门的CMOS,就像具有特殊数据类型和数据布局的GPU。或者,计算机可以采用新的物理设备,例如带有非晶体管设备的神经形态结构(例如忆阻器)。
总之,AGI可能会有1000倍或更多的改进。换句话说,热衷于AGI的人可能会计划到2030年达到181 GFLOPS/美元。然而,它们将被归类为人工智能机器,而不是顶级超级计算机。
卢基:谢谢,Erik!
- 评述中补充的注释:Landauer仅对“不可逆”计算提出了“kT阶上”的下限。据我所知,“朗道尔的极限”这个说法是后来由别人发明的。根据我的经验,“朗道尔极限”这个词经常被用作一般的极限。↩
你喜欢这篇文章吗?你可以享受我们的另一个对话的帖子,包括: