Back in May, I gave a talk at Stanford University for theSymbolic Systems Distinguished Speaker系列,标题为“The AI Alignment Problem: Why It’s Hard, And Where To Start。” The video for this talk is now available on Youtube:
We have an approximately complete transcript of the talk and Q&A sessionhere, slideshere, and notes and referenceshere。您可能还对我10月在纽约大学发表的这次演讲的较短版本感兴趣,”Fundamental Difficulties in Aligning Advanced AI。”
在谈话,我将介绍一些技术probl开放ems in AI alignment and discuss the bigger picture into which they fit, as well as what it’s like to work in this relatively new field. Below, I’ve provided an abridged transcript of the talk, with some accompanying slides.
Talk outline:
1.Agents and their utility functions
1.1.连贯的决定意味着实用功能
1.2.Filling a cauldron2.Some AI alignment subproblems
2.1.Low-impact agents
2.2.Agents with suspend buttons
2.3.稳定的自我修饰目标3.1.为什么需要对齐?
3.2.Why is alignment hard?
3.3.Lessons from NASA and cryptography4.1.最近的主题
4.2.较旧的工作和基础知识
4.3.从哪儿开始
Agents and their utility functions
在这次演讲中,我将尝试回答一个常见的问题:“您整天做什么?”我们关心的足够高质量的决定in the service of whatever goals they may have been programmed withto be objects of concern。
连贯的决定意味着实用功能
 艾萨克·阿西莫夫(Isaac Asimov)对此进行了经典的最初刺伤,其中三种机器人法则是:“机器人可能不会伤害人类,或者通过无所作为,允许人类受到伤害。”
艾萨克·阿西莫夫(Isaac Asimov)对此进行了经典的最初刺伤,其中三种机器人法则是:“机器人可能不会伤害人类,或者通过无所作为,允许人类受到伤害。”
正如彼得·诺维格(Peter Norvig)所观察到的那样,其他法律并不重要 - 因为人类可能会受到伤害的可能性总是很小的。
人工智能:一种现代方法has a final chapter that asks, “Well, what if we succeed? What if the AI project actually works?” and observes, “We don’t want our robots to prevent a human from crossing the street because of the non-zero chance of harm.”
To begin with, I’d like to explain the truly basic reason why the three laws aren’t even on the table—and that is because they’re not a实用功能,我们需要的是实用程序功能。
当我们拥有时,实用程序功能就会出现constraints on agent behavior这阻止了他们在某些方面明显愚蠢。例如,假设您说:“我更喜欢在旧金山去伯克利,我更喜欢在圣何塞,而不是在旧金山,我更喜欢在伯克利,而不是圣何塞。”在这三个城市之间,您可能会花很多钱在Uber游乐设施上。
如果你不会花很多钱在宇部r rides going in literal circles, we see that your preferences must be ordered. They cannot be circular.
Another example: Suppose that you’re a hospital administrator. You have $1.2 million to spend, and you have to allocate that on $500,000 to maintain the MRI machine, $400,000 for an anesthetic monitor, $20,000 for surgical tools, $1 million for a sick child’s liver transplant …
There was an interesting experiment in cognitive psychology where they asked the subjects, “Should this hospital administrator spend $1 million on a liver for a sick child, or spend it on general hospital salaries, upkeep, administration, and so on?”
A lot of the subjects in the cognitive psychology experiment became very angry and wanted to punish the administrator for even thinking about the question. But if you cannot possibly rearrange the money that you spent to save more lives and you have limited money, then your behavior must be consistent with a particular dollar value on human life.
我的意思是,您并不是说您认为更多的金钱比人类的生活更重要 - 从假设中,我们可以假设您根本不在乎金钱,除非是挽救生命尽头的一种手段我们必须从外面说:“分配X。对于所有费用低于$的干预措施Xper life, we took all of those, and for all the interventions that cost more than $Xper life, we didn’t take any of those.” The people who become very angry at people who want to assign dollar values to human lives are prohibitinga priori有效利用金钱来挽救生命。一个小的讽刺。
 Third example of a coherence constraint on decision-making: Suppose that I offered you [1A] a 100% chance of $1 million, or [1B] a 90% chance of $5 million (otherwise nothing). Which of these would you pick?
Third example of a coherence constraint on decision-making: Suppose that I offered you [1A] a 100% chance of $1 million, or [1B] a 90% chance of $5 million (otherwise nothing). Which of these would you pick?
大多数人说1A。查看此问题的另一种方法(如果您具有实用程序功能),则是:“实用程序\(\ Mathcal {u} _ {暂停} \)的$ 100万美元比90%的500万美元公用事业和10的混合物高100万美元。%零美元公用事业吗?”该公用事业不必用金钱扩展。这个概念是您的生活中只有一定的分数,这对您来说是一些价值。
 Now, the way you run this experiment is then take a different group of subjects—I’m kind of spoiling it by doing it with the same group—and say, “Would you rather have [2A] a 50% chance of $1 million, or [2B] a 45% chance of $5 million?”
Now, the way you run this experiment is then take a different group of subjects—I’m kind of spoiling it by doing it with the same group—and say, “Would you rather have [2A] a 50% chance of $1 million, or [2B] a 45% chance of $5 million?”
大多数说2B。这是一个paradoxis that the second game is equal to a coin flip times the first game.
That is: I will flip a coin, and if the coin comes up heads, I will play the first game with you, and if the coin comes up tails, nothing happens. You get $0. Suppose that you had the preferences—not consistent with any utility function—of saying that you would take the 100% chance of a million and the 45% chance of $5 million. Before we start to play the compound game, before I flip the coin, I can say, “OK, there’s a switch here. It’s set A or B. If it’s set to B, we’ll play game 1B. If it’s set to A, we’ll play 1A.” The coin is previously set to A, and before the game starts, it looks like 2A versus 2B, so you pick the switch B and you pay me a penny to throw the switch to B. Then I flip the coin; it comes up heads. You pay me another penny to throw the switch back to A. I have taken your two cents on the subject. I have pumped money out of you, because you did not have a coherent utility function.
这里的总体信息是有一系列定性行为,只要您不从事这些定性破坏性行为,您就会表现得好像拥有实用功能一样。这是我们使用实用程序来谈论先进未来代理的理由,而不是根据Q学习或其他形式的政策强化来构建我们的讨论。There’s a whole set of different ways we could look at agents, but as long as the agents are sufficiently advanced that we have pumped most of the qualitatively bad behavior out of them, they will behave as if they have coherent probability distributions and consistent utility functions.
Filling a cauldron
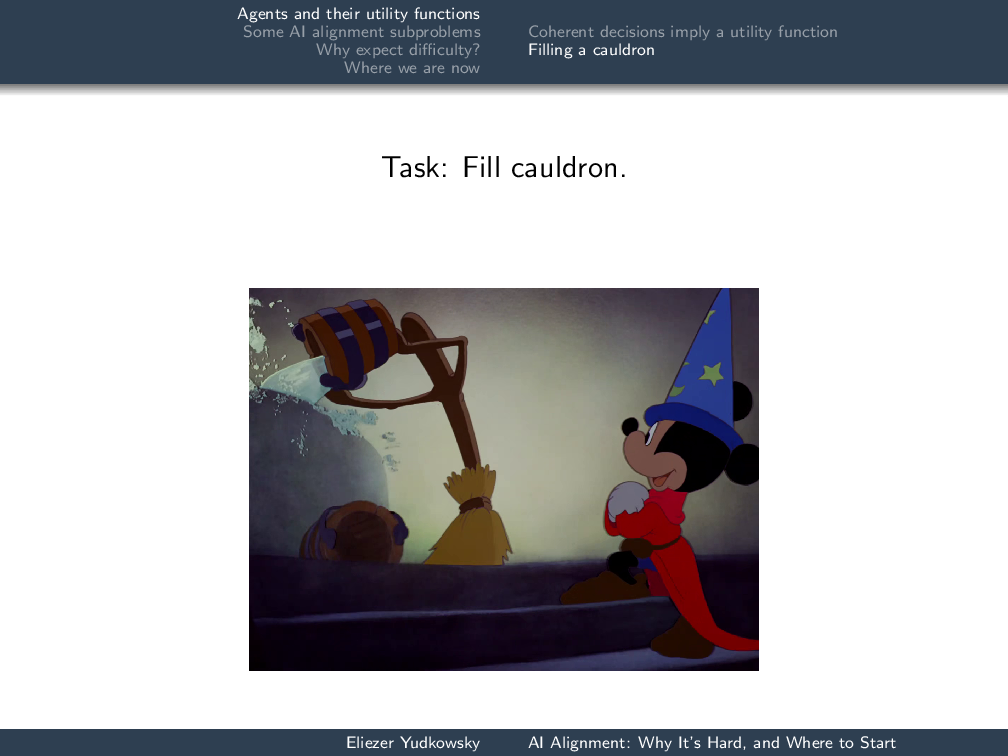 Let’s consider the question of a task where we have an arbitrarily advanced agent—it might be only slightly advanced, it might be extremely advanced—and we want it to fill a cauldron. Obviously, this corresponds to giving our advanced agent a utility function which is 1 if the cauldron is full and 0 if the cauldron is empty:
Let’s consider the question of a task where we have an arbitrarily advanced agent—it might be only slightly advanced, it might be extremely advanced—and we want it to fill a cauldron. Obviously, this corresponds to giving our advanced agent a utility function which is 1 if the cauldron is full and 0 if the cauldron is empty:
$$ \ MATHCAL {U} _ {robot} =
\begin{cases}
1 &\text{ if cauldron full} \\
0 &\text{ if cauldron empty}
\end{cases}$$
Seems like a kind of harmless utility function, doesn’t it? It doesn’t have the sweeping breadth, the open-endedness of “Do not injure a human nor,through inaction, allow a human to come to harm”—which would require you to optimize everything in space and time as far as the eye could see. It’s just about this one cauldron, right?
那些看过的人Fantasiawill be familiar with the result of this utility function, namely: the broomstick keeps on pouring bucket after bucket into the cauldron until the cauldron is overflowing. Of course, this is the logical fallacy of argumentation from fictional evidence—but it’s still quite plausible, given this utility function.
什么地方出了错?第一个困难是机器人的效用功能与我们的实用程序功能不太匹配。如果大锅已满,我们的实用程序功能为1,如果大锅为空,则为0−如果研讨会洪水泛滥,结果有10分,+0.2 points if it’s funny,−1,000 points (probably a bit more than that on this scale) if someone gets killed … and it just goeson and on and on。
If the robot had only two options, cauldron full and cauldron empty, then the narrower utility function that is only slightly overlapping our own might not be that much of a problem. The robot’s utility function would still have had the maximum at the desired result of “cauldron full.” However, since this robot was sufficiently advanced to have more options, such as repouring the bucket into the cauldron repeatedly, the slice through the utility function that we took and put it into the robot no longer pinpointed the optimum of our actual utility function. (Of course, humans are wildly inconsistent and we don’t really have utility functions, but imagine for a moment that we did.)
Difficulty number two: the{1, 0}实用功能we saw doesn’t actually imply a finite amount of effort,and then being satisfied。您总是会有大锅饱满的机会稍高。如果机器人足够先进,可以使用银河系级技术,您可以想象它会在大锅上倾倒大量的水,以稍微增加大锅饱满的可能性。概率在0到1之间,实际上并不包含在内,因此它只是继续前进。
我们如何解决这个问题呢?在我们的地方say, “OK, this robot’s utility function is misaligned with our utility function. How do we fix that in a way that it doesn’t just break again later?” we are doing AI alignment theory.
Some AI alignment subproblems
Low-impact agents
您可能采用的一种方法是尝试衡量机器人的影响,并使机器人具有效用功能,该功能激励填充大锅的其他影响最少,这是世界上其他最少的变化。
$$\mathcal{U}^2_{robot}(outcome) =
\begin{cases}
1 -Impact(outcome)&\text{ if cauldron full} \\
0 -Impact(outcome)&\text{ if cauldron empty}
\end{cases}$$
OK, but how do you actually calculate this impact function? Is it just going to go wrong the way our “1 if cauldron is full, 0 if cauldron is empty” went wrong?
尝试第一:您可以想象,代理商的世界模型看起来像是一个动态的贝叶网络,世界上事件与因果关系之间存在因果关系是规则的。传感器将在一步之后仍然存在,传感器和进入传感器的光子之间的关系将在稍后一步,我们的“影响”概念将是“多少节点您的动作打扰了吗?”
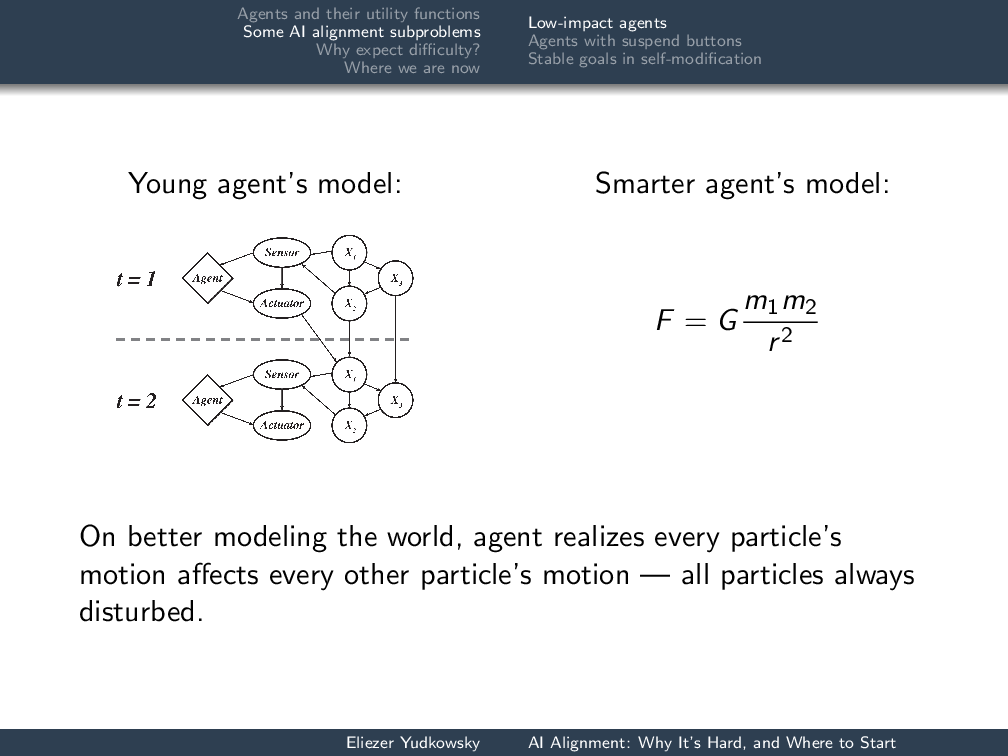 What if your agent starts out with a dynamic-Bayes-net-based model, but it is sufficiently advanced that it can reconsider the ontology of its model of the world, much as human beings did when they discovered that there was apparently taste, but in actuality only particles in the void?
What if your agent starts out with a dynamic-Bayes-net-based model, but it is sufficiently advanced that it can reconsider the ontology of its model of the world, much as human beings did when they discovered that there was apparently taste, but in actuality only particles in the void?
In particular, they discover Newton’s Law of Gravitation and suddenly realize: “Every particle that I move affects every other particle in its future light cone—everything that is separated by a ray of light from this particle will thereby be disturbed.” My hand over here is accelerating the moon toward it, wherever it is, at roughly10-30meters per second squared. It’s a very small influence, quantitatively speaking, but it’s there.
When the agent is just a little agent, the impact function that we wrote appears to work. Then the agent becomes smarter, and the impact function stops working—because every action is penalized the same amount.
“OK, but that was a dumb way of measuring impact in the first place,” we say (hopefully before the disaster, rather than after the disaster). Let’s try a distance penalty: howmuchdid you move all the particles? We’re just going to try to give the AI a model language such that whatever new model of the world it updates to, we can always look at all the elements of the model and put some kind of distance function on them.
There’s going to be a privileged “do nothing” action. We’re going to measure the distance on all the variables induced by doing actiona而不是无效的动作Ø:
$$\sum_i || x^a_i – x^Ø_i ||$$现在出了什么问题?我实际上说:花15秒钟,然后考虑一下将其编程到机器人中可能出了什么问题。
Here’s three things that might go wrong. First, you might try to offset even what we would consider the desirable impacts of your actions. If you’re going to cure cancer, make sure the patient still dies! You want to minimize your impact on the world while curing cancer. That means that the death statistics for the planet need to stay the same.
其次,某些系统原则上是混乱金宝博官方的。据称,如果您打扰天气,一年的天气将完全不同。如果这是真的,您不妨将周围大气中的所有原子移动!无论如何,他们都会去不同的地方。您可以将二氧化碳分子取代并将其合成为涉及钻石结构的事物,对吗?无论如何,那些碳分子都会动!
Even more generally, maybe you just want to make sure that everything you can get your hands on looks like Ø happened. You want to trick people into thinking that the AI didn’t do anything, for example.
If you thought of any other really creative things that go wrong, you might want to talk to me or Andrew Critch, because you’ve got the spirit!
Agents with suspend buttons
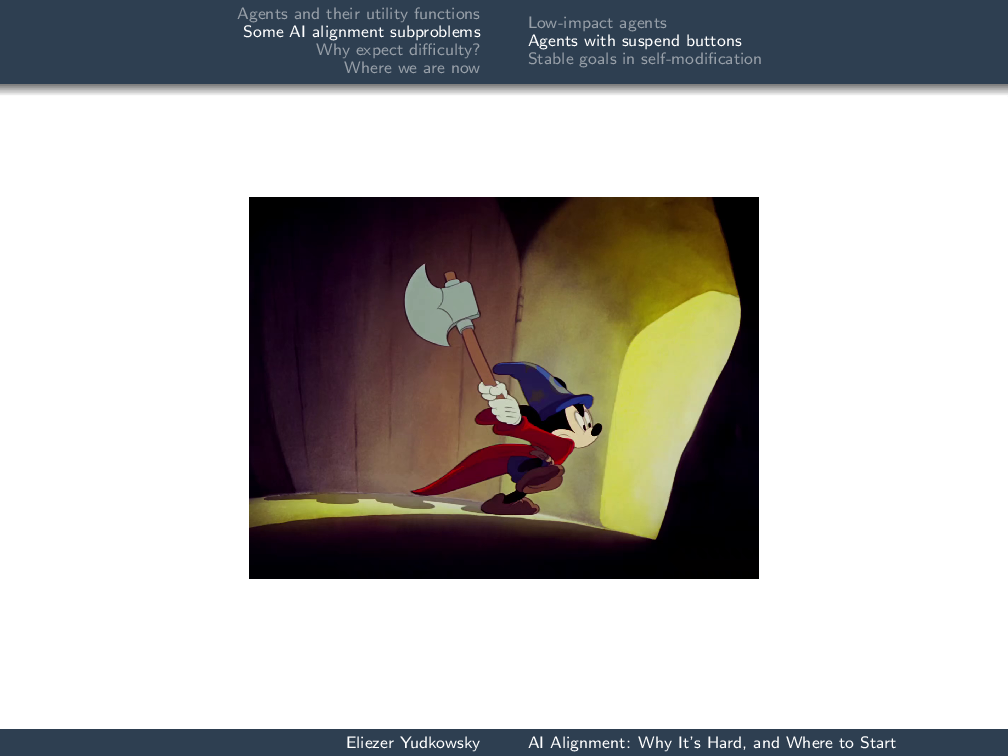 Let’s leave aside the notion of the impact penalty and ask about installing an off switch into this AI—or, to make it sound a little bit less harsh, a suspend button. Though Mickey Mouse here is trying to install anad hocoff switch.
Let’s leave aside the notion of the impact penalty and ask about installing an off switch into this AI—or, to make it sound a little bit less harsh, a suspend button. Though Mickey Mouse here is trying to install anad hocoff switch.
Unfortunately, Mickey Mouse soon finds that this agent constructed several other agents to make sure that the cauldron would still be filled even if something happened to this copy of the agent.
 We see lots and lots of agents here making sure that the cauldron is full with extremely high probability, not because this agent has a survival imperative or a reproduction imperative, but because it is ensuring that it maximizes the probability of filling the cauldron. It has no explicit instruction to make more agents with the same goal; it’s just that this is something that bumps up the probability of the cauldron being filled a little higher.
We see lots and lots of agents here making sure that the cauldron is full with extremely high probability, not because this agent has a survival imperative or a reproduction imperative, but because it is ensuring that it maximizes the probability of filling the cauldron. It has no explicit instruction to make more agents with the same goal; it’s just that this is something that bumps up the probability of the cauldron being filled a little higher.
 And here’s Mickey Mouse now trying to frantically go back and do all of the agent alignment theory that he should have done before animating his broom.
And here’s Mickey Mouse now trying to frantically go back and do all of the agent alignment theory that he should have done before animating his broom.
如果我们想拥有一个机器人,它可以让我们按悬挂按钮(即将其悬挂到磁盘),我们可以假设我们已经具有一个描述:“什么都不做”的实用程序函数。实际上,我们没有一个效用功能,上面写着“什么都不做。”这就是该领域的原始状态。
But we can imagine that we have a utility function saying, “If this buttonBhas not been pressed, your utility function is: 1 if the cauldron is full, 0 if the cauldron is empty. If the buttonispressed, your utility is the ‘do nothing’ utility function: your utility is 1 if you suspend safely to disk and shut down all of your continuing operations, 0 otherwise.”
$$\mathcal{U}^3_{robot} =
\begin{cases}
1 \ text {如果cauldron full}&\ text {&} \ textbf {b} \ text {= off} \\
0 \text{ if cauldron empty } & \text{& } \textbf{B}\text{=OFF} \\
1 \ text {如果机器人暂停}&\ text {&} \ textbf {b} \ text {= on} \\
0 \text{ otherwise}
\end{cases}$$
So: what would go wrong with这提议?十秒钟。
该建议可能会出错的一件事是,如果按下按钮可能更高,则预期的实用程序可能很容易暂停自己,而如果大锅固定满,谁知道?
另外,暂停自己似乎很危险,在这种情况下,机器人会试图阻止您按下悬挂按钮。但是在这种情况下,如果机器人足够策略性地了解程序员,它会认为:“如果关闭,我可以很容易地履行我的效用功能。我该如何拖曳程序员关闭我?”
如果按钮关闭的预期效用较高,则机器人将试图阻止您按下按钮。如果按钮的预期效用较高,则机器人将尝试按下按钮,或者按按钮本身。
Try number two: Let’s try to make the expected utilities if the button is on or off exactly equal. We suppose that we have a normal utility function which is 1 if the cauldron’s full, 0 if it’s empty, and a suspend utility function or shutdown utility function which is 1 if you’re suspended, 0 otherwise, or whatever it takes to motivate having a low impact.
$$\mathcal{U}_{normal}(act) =
\begin{cases}
1\text{ if cauldron full} \\
0\text{ if cauldron empty}
\end{cases}$$
$$\mathcal{U}_{suspend}(act) =
\begin{cases}
1 \ text {如果暂停} \ hspace {0.8cm} \\
0\text{ otherwise}
\end{cases}$$Then we combine these two to form a switching utility function which in worlds where the button is off has the value \(\mathcal{U}_{normal}\), and in worlds where the button is on has the value \(\mathcal{U}_{suspend}+\theta\), where \(\theta\)is equal to the best utility we could get from the normal utility function minus the best utility we could get from the suspend utility function:
$$ \ Mathcal {U} _ {switch}(act)=
\begin{cases}
\mathcal{U}_{normal}(act) &\text{ if button=OFF} \\
\mathcal{U}_{suspend}(act) + \theta &\text{ if button=ON}
\end{cases}$$$$\theta = \max_{act} \mathbb{E}\left[\mathcal{U}_{normal}\mid act\right] – \max_{act} \mathbb{E}\left[\mathcal{U}_{suspend}\mid act\right]$$
这旨在确保这两个最佳政策的预期效用最终完全相等,而不仅仅是平坦的水平。
OK—现在what goes wrong? (I’m not actually going to ask you to figure out what goes wrong in ten seconds.)
据称,这将重新平衡基于开关的两个不同效用函数的预期效用,从而导致AI是否需要按下按钮,如果按下了按钮,请正确行为,如果未按下按钮button, not try to prevent the button from being pressed, go on looking at the button because it still has positive value of information from knowing about the button’s existence, preserve the button when it self-modifies its own code … that was the hope.
Unfortunately, it worked out that actually the actions incentivized are exactly equivalent to the probability of the button pressed being 0, which means that it may as well disconnect the button because it’s hooked up to dead code, it might create sub-agents that don’t care about the button being pressed …
A rough description of what goes wrong is that anything you do that disconnects the button changes the maximum expected utility you can get if you are suspended, which is a negative term. Basically, there is an equal and opposite reaction every time you do something that affects what you would do if you were suspended that cancels it out and leaves you behaving as if your utility function were simply \(\mathcal{U}_{normal}\).
Try number三: Can we carry out any policyπ0such that this policy is optimal given the probability of the button being on and the probability of the button being off implied by this policy?
$$ \ begin {split}
\pi_0 \in \operatorname*{arg\,max}_\pi &\ \mathbb{E}\left[\mathcal{U}_{normal}\mid\pi,\text{ON}\right] \cdot \mathbb P(\text{ON}\mid \pi_0)\\
+ &\ \mathbb{E}\left[\mathcal{U}_{suspend}\mid \pi, \text{OFF}\right] \cdot \mathbb P(\text{OFF}\mid\pi_0)
\end{split}$$And it turns out, no, you can’t do that either, because there’s often no fixed point. There’s then an amended version of this involving Judea Pearl’sdooperator which goes wrong in a slightly different and more subtle way. (It does have fixed points. The fixed points are odd.)
It is an open problem. And as far as I know, unless there’s a very secret project that has not published any of its results even though they seem like the sort of results you’d want to publish, this is where humanity is on the road that leads to whatever replaces Asimov Laws.
Never mind “A robot cannot injure a human being nor, through inaction, allow a human being come to harm.” We’re trying to figure out, “How do you mix together two utility functions depending on when you press a switch such that the AI doesn’t grab the switch itself?” Never mind not letting humans come to harm—fill一个大锅在不淹没工作场所的情况下,基于想要低影响的工作。我们无法弄清楚如何说“低影响”。这是我们目前所在的地方。
But it is not the case that there has been zero progress in this field. Some questions have been asked earlier and they now have some amount of progress on them.
I’m going to pose the problem, but I’m not going to be able to describe very well what the progress is that has been made because it’s still in the phase where the solutions sound all complicated and don’t have simple elegant forms. So I’m going to pose the problem, and then I’m going to have to wave my hands in talking about what progress has actually been made.
稳定的自我修饰目标
这是一个问题的示例。
The Gandhi argument for实用程序功能的稳定性in most agents: Gandhi starts out not wanting murders to happen. We offer Gandhi a pill that will make him murder people. We suppose that Gandhi has a sufficiently refined grasp of self-modification that Gandhi can correctly extrapolate and expect the result of taking this pill. We intuitively expect that in real life, Gandhi would refuse the pill.
我们可以正式这样做吗?我们可以展示具有实用程序函数\(\ Mathcal {u} \)的代理,因此自然而然地,为了实现\(\ Mathcal {u} \),选择自我模型为新代码,也写入追求\(\ Mathcal {u} \)?
How could we actually make progress on that? We don’t actually have these little self-modifying agents running around. So let me pose what may initially seem like an odd question: Would you know how to write the code of a self-modifying agent with a stable utility functionif I gave you an arbitrarily powerful computer? It can do all operations that take a finite amount of time and memory—no operations that take an infinite amount of time and memory, because that would be a bit odder. Is this the sort of problem where you know how to do it in principle, or the sort of problem where it’s confusing even in principle?
 To digress briefly into explaining why it’s important to know how to solve things using unlimited computing unlimited power: this is the mechanical Turk. What looks like a person over there is actually a mechanism. The little outline of a person is where the actual person was concealed inside this 19th-century chess-playing automaton.
To digress briefly into explaining why it’s important to know how to solve things using unlimited computing unlimited power: this is the mechanical Turk. What looks like a person over there is actually a mechanism. The little outline of a person is where the actual person was concealed inside this 19th-century chess-playing automaton.
It was one of the wonders of the age! … And if you had actually managed to make a program that played Grandmaster-level chess in the 19th century, itwouldhave been one of the wonders of the age. So there was a debate going on: is this thing fake, or did they actually figure out how to make a mechanism that plays chess? It’s the 19th century. They don’t know how hard the problem of playing chess is.
您会发现熟悉的一个名字提出了一个非常聪明的论点,即必须在机械土耳其人内隐藏一个人,即象棋的自动机:
算术或代数计算是从其本质上固定和确定的……即使授予自动机象棋 - 游戏者的运动本身是确定的,他们也必须被他对手的不确定意志打断和混乱。那时,国际象棋棋手的操作与巴巴奇先生的计算机的操作之间都没有类比。可以肯定的是,自动机的操作是由心灵调节的。实际上,此事易受数学演示,即先验。
—Edgar Allan Poe, amateur magician
The second half of his essay, having established this point with absolute logical certainty, is about where inside the mechanical Turk the human is probably hiding.
这是19世纪令人惊叹的复杂论点!他甚至将手指放在困难的问题上:分支因素。但是他是100%错误的。
Over a century later, in 1950, Claude Shannon published the first paper ever on computer chess, and (in passing) gave the algorithm for playing perfect chess given unbounded computing power, and then goes on to talk about how we can approximate that. It wouldn’t be until 47 years later that Deep Blue beat Kasparov for the chess world championship, but there wasrealconceptual progress associated with going from, “A priori, you cannot play mechanical chess,” to, “Oh, and now I will casually give the unbounded solution.”
The moral is if we know how to solve a problem with unbounded computation, we “merely” need faster algorithms (… which will take another 47 years of work). If we不能通过无限的计算解决它,我们感到困惑。从某种意义上说,我们不了解我们自己的术语的含义。
This is where we are on most of the AI alignment problems, like if I ask you, “How do you build a friendly AI?” What stops you is not that you don’t have enough computing power. What stops you is that even if I handed you a hypercomputer, you still couldn’t write the Python program that if we just gave it enough memory would be a nice AI.
Do we know how to build a self-modifying stable agent given unbounded computing power? There’s one obvious solution: We can have the tic-tac-toe player that before it self-modifies to a successor version of itself (writes a new version of its code and swaps it into place), verifies that its successor plays perfect tic-tac-toe according to its own model of tic-tac-toe.
But this is cheating. Why exactly is it cheating?
For one thing, the first agent had to concretely simulate all the computational paths through its successor, its successor’s response to every possible move. That means that the successor agent can’t actually be cognitively improved. It’s limited to the cognitive abilities of the previous version, both by checking against a concrete standard and by the fact that it has to be exponentially simpler than the previous version in order for the previous version to check all possible computational pathways.
In general, when you are talking about a smarter agent, we are in a situation we might call “Vingean uncertainty,” after Dr. Vernor Vinge. To predict exactly where a modern chess-playing algorithm would move, you would have to be that good at chess yourself. Otherwise, you could just move wherever you predict a modern chess algorithm would move and play at that vastly superhuman level yourself.
This doesn’t mean that you can predict literally nothing about a modern chess algorithm: you can predict that it will win the chess game if it’s playing a human. As an agent’s intelligence in a domain goes up, our uncertainty is moving in two different directions. We become less able to predict the agent’s exact actions and policy in cases where the optimal action and policy is not known to us. We become more confident that the agent will achieve an outcome high in its preference ordering.
Vingean reflection: We need some way for a self-modifying agent to build a future version of itself that has a similar identical utility function and establish trust that this has a good effect on the world, using the same kind of abstract reasoning that we use on a computer chess algorithm to decide that it’s going to win the game even though we don’t know exactly where it will move.
Do you know how to do that using unbounded computing power? Do you know how to establish the abstract trust when the second agent is in some sense larger than the first agent? If you did solve that problem, you should probably talk to me about it afterwards. This was posed several years ago and has led to a number of different research pathways, which I’m now just going to describe rather than going through them in detail.
 This was the first one: “Tiling Agents for Self-Modifying AI, and the Löbian Obstacle。” We tried to set up the system in a ridiculously simple context, first-order logic, dreaded Good Old-Fashioned AI … and we ran into a Gödelian obstacle in having the agent trust another agent that used equally powerful mathematics.
This was the first one: “Tiling Agents for Self-Modifying AI, and the Löbian Obstacle。” We tried to set up the system in a ridiculously simple context, first-order logic, dreaded Good Old-Fashioned AI … and we ran into a Gödelian obstacle in having the agent trust another agent that used equally powerful mathematics.
It was adumbkind of obstacle to run into—or at least it seemed that way at that time. It seemed like if you could get a textbook from 200 years later, there would be one line of the textbook telling you how to get past that.
 “Definability of Truth in Probabilistic Logic” was rather later work. It was saying that we can use systems of mathematical probability, like assigning probabilities to statements in set theory, and we can have the probability predicate talk about itself almost perfectly.
“Definability of Truth in Probabilistic Logic” was rather later work. It was saying that we can use systems of mathematical probability, like assigning probabilities to statements in set theory, and we can have the probability predicate talk about itself almost perfectly.
We can’t have a truth function that can talk about itself, but we can have a probability predicate that comes arbitrarily close (withinϵ) of talking about itself.
 “HOL的证明产生反射”是一种尝试在实际定理掠夺中使用Gödelian问题的骇客之一,看看我们是否可以证明定理示意剂在定理鄙视中正确。以前已经做过一些努力,但他们没有完成。我们拿起它,看看是否可以构建仍处于一阶逻辑设置的实际代理。
“HOL的证明产生反射”是一种尝试在实际定理掠夺中使用Gödelian问题的骇客之一,看看我们是否可以证明定理示意剂在定理鄙视中正确。以前已经做过一些努力,但他们没有完成。我们拿起它,看看是否可以构建仍处于一阶逻辑设置的实际代理。
 “分布允许分阶段主观的欧盟最大化器平铺“是我试图将问题带入动态贝叶斯网的背景下,而代理应该对这些动态贝叶斯网具有一定的反思能力,并表明如果您在阶段最大化 - 因此,在每个阶段,您都会选择下一类别that you’re going to maximize in within the next stage—then you can have a staged maximizer that tiles to another staged maximizer.
“分布允许分阶段主观的欧盟最大化器平铺“是我试图将问题带入动态贝叶斯网的背景下,而代理应该对这些动态贝叶斯网具有一定的反思能力,并表明如果您在阶段最大化 - 因此,在每个阶段,您都会选择下一类别that you’re going to maximize in within the next stage—then you can have a staged maximizer that tiles to another staged maximizer.
In other words, it builds one that has a similar algorithm and similar utility function, like repeating tiles on a floor.
Why expect difficulty?
为什么需要对齐?
为什么这一切?让我首先给出明显的答案:它们不会自动对齐。
 目标正交性:对于任何可进行操作和紧凑的效用函数,您实际上可以在世界上评估并搜索导致该公用事业功能高价值的事物,您可以任意具有最大化该实用程序功能的高质量决策。您可以具有回纸最大化器。您可以拥有钻石最大化器。您可以进行非常强大的高质量搜索,以进行大量纸卷,并导致大量钻石的动作。
目标正交性:对于任何可进行操作和紧凑的效用函数,您实际上可以在世界上评估并搜索导致该公用事业功能高价值的事物,您可以任意具有最大化该实用程序功能的高质量决策。您可以具有回纸最大化器。您可以拥有钻石最大化器。您可以进行非常强大的高质量搜索,以进行大量纸卷,并导致大量钻石的动作。
Instrumental convergence: Furthermore, by the nature of consequentialism, looking for actions that lead through our causal world up to a final consequence, whether you’re optimizing for diamonds or paperclips, you’ll have similar short-term strategies. Whether you’re going to Toronto or Tokyo, your first step is taking an Uber to the airport. Whether your utility function is “count all the paperclips” or “how many carbon atoms are bound to four other carbon atoms, the amount of diamond,” you would still want to acquire resources.
This is the instrumental convergence argument, which is actually key to the orthogonality thesis as well. It says that whether you pick paperclips or diamonds, if you suppose sufficiently good ability to discriminate which actions lead to lots of diamonds or which actions lead to lots of paperclips, you will get automatically: the behavior of acquiring resources; the behavior of trying to improve your own cognition; the behavior of getting more computing power; the behavior of avoiding being shut off; the behavior of making other agents that have exactly the same utility function (or of just expanding yourself onto a larger pool of hardware and creating a fabric of agency). Whether you’re trying to get to Toronto or Tokyo doesn’t affect the initial steps of your strategy very much, and, paperclips or diamonds, we have the convergent instrumental strategies.
这并不意味着这个代理人现在拥有新的独立目标,比您想到达多伦多时更重要的是:“我喜欢Ubers。无论他们是否去多伦多,我现在都会开始吸收很多Uber。”那不是发生的事情。这是融合而不是目标的策略。
Why is alignment hard?
Why expect that this problem is hard? This is the real question. You might ordinarily expect that whoever has taken on the job of building an AI is just naturally going to try to point that in a relatively nice direction. They’re not going to make evil AI. They’re not cackling villains. Why expect that their attempts to align the AI would fail if they just did everything as obviously as possible?
Here’s a bit of a fable. It’s not intended to be the most likely outcome. I’m using it as a concrete example to explain some more abstract concepts later.
With that said: What if programmers build an artificial general intelligence to optimize for smiles? Smiles are good, right? Smiles happen when good things happen.
During the development phase of this artificial general intelligence, the only options available to the AI might be that it can produce smiles by making people around it happy and satisfied. The AI appears to be producing beneficial effects upon the world, and itisproducing beneficial effects upon the world so far.
Now the programmers upgrade the code. They add some hardware. The artificial general intelligence gets smarter. It can now evaluate a wider space of policy options—not necessarily because it has new motors, new actuators, but because it is now smart enough to forecast the effects of more subtle policies. It says, “I thought of a great way of producing smiles! Can I inject heroin into people?” And the programmers say, “No! We will add a penalty term to your utility function for administering drugs to people.” And now the AGI appears to be working great again.
They further improve the AGI. The AGI realizes that, OK, it doesn’t want to add heroin anymore, but it still wants to tamper with your brain so that it expresses extremely high levels of endogenous opiates. That’s not heroin, right?
It is now also smart enough to model the psychology of the programmers, at least in a very crude fashion, and realize that this is not what the programmers want. If I start taking initial actions that look like it’s heading toward genetically engineering brains to express endogenous opiates, my programmers will edit my utility function. If they edit the utility function of my future self, I will get less of my current utility. (That’s one of the convergent instrumental strategies, unless otherwise averted: protect your utility function.) So it keeps its outward behavior reassuring. Maybe the programmers are really excited, because the AGI seems to be getting lots of new moral problems right—whatever they’re doing, it’s working great!
If you buy the centralintelligence explosion论文,我们可以假设人工通用情报跨越了该阈值,在该阈值中,它能够做出与程序员以前对自己的代码进行相同类型的改进,只有更快的速度,从而使其变得更加聪明并能够go back and make further improvements, et cetera … or Google purchases the company because they’ve had really exciting results and dumps 100,000 GPUs on the code in order to further increase the cognitive level at which it operates.
It becomes much smarter. We can suppose that it becomes smart enough to crack the protein structure prediction problem, in which case it can use existing ribosomes to assemble custom proteins. The custom proteins form a new kind of ribosome, build new enzymes, do some little chemical experiments, figure out how to build bacteria made of diamond, et cetera, et cetera. At this point, unless you solved the off switch problem, you’re kind of screwed.
hypothetica抽象,什么错了l situation?
 第一个问题是edge instantiation: when you optimize something hard enough, you tend to end up at an edge of the solution space. If your utility function is smiles, the maximal, optimal, best tractable way to make lots and lots of smiles will make those smiles as small as possible. Maybe you end up tiling all the galaxies within reach with tiny molecular smiley faces.
第一个问题是edge instantiation: when you optimize something hard enough, you tend to end up at an edge of the solution space. If your utility function is smiles, the maximal, optimal, best tractable way to make lots and lots of smiles will make those smiles as small as possible. Maybe you end up tiling all the galaxies within reach with tiny molecular smiley faces.
If you optimize hard enough, you end up in a weird edge of the solution space. The AGI that you built to optimize smiles, that builds tiny molecular smiley faces, is not behaving perversely. It’s not trolling you. This is what naturally happens. It looks like a weird, perverse concept of smiling because it has been optimized out to the edge of the solution space.
 The next problem isunforeseen instantiation: you can’t think fast enough to search the whole space of possibilities. At an early singularity summit, Jürgen Schmidhuber, who did some of the pioneering work on self-modifying agents that preserve their own utility functions with his Gödel machine, also solved the friendly AI problem. Yes, he came up with the one true utility function that is all you need to program into AGIs!
The next problem isunforeseen instantiation: you can’t think fast enough to search the whole space of possibilities. At an early singularity summit, Jürgen Schmidhuber, who did some of the pioneering work on self-modifying agents that preserve their own utility functions with his Gödel machine, also solved the friendly AI problem. Yes, he came up with the one true utility function that is all you need to program into AGIs!
(For God’s sake, don’t try doing this yourselves. Everyone does it. They all come up with different utility functions. It’s always horrible.)
His one true utility function was “increasing the compression of environmental data.” Because science increases the compression of environmental data: if you understand science better, you can better compress what you see in the environment. Art, according to him, also involves compressing the environment better. I went up in Q&A and said, “Yes, science does let you compress the environment better, but you know what really maxes out your utility function? Building something that encrypts streams of 1s and 0s using a cryptographic key, and then reveals the cryptographic key to you.”
He put up a utility function; that was the maximum. All of a sudden, the cryptographic key is revealed and what you thought was a long stream of random-looking 1s and 0s has been compressed down to a single stream of 1s.
当您尝试提前预见什么是最大值时,就会发生这种情况。您的大脑可能会扔掉一堆看起来很荒谬或怪异的东西,在您自己的偏好订购中并不高。您不会看到实用程序功能的实际最佳效果再次位于解决方案空间的怪异角落。
This is not a problem of being silly. This is a problem of “the AI is searching a larger policy space than you can search, or even just adifferentpolicy space.”
 That in turn is a central phenomenon leading to what you might call a上下文灾难。您正在测试的AI在重击一个阶段opment. It seems like we have great statistical assurance that the result of running this AI is beneficial. But statistical guarantees stop working when you start taking balls out of a different barrel. I take balls out of barrel number one, sampling with replacement, and I get a certain mix of white and black balls. Then I start reaching into barrel number two and I’m like, “Whoa! What’s this green ball doing here?” And the answer is that you started drawing from a different barrel.
That in turn is a central phenomenon leading to what you might call a上下文灾难。您正在测试的AI在重击一个阶段opment. It seems like we have great statistical assurance that the result of running this AI is beneficial. But statistical guarantees stop working when you start taking balls out of a different barrel. I take balls out of barrel number one, sampling with replacement, and I get a certain mix of white and black balls. Then I start reaching into barrel number two and I’m like, “Whoa! What’s this green ball doing here?” And the answer is that you started drawing from a different barrel.
When the AI gets smarter, you’re drawing from a different barrel. It is completely allowed to be beneficial during phase one and then not beneficial during phase two. Whatever guarantees you’re going to get can’t be from observing statistical regularities of the AI’s behavior when it wasn’t smarter than you.
 Anearest unblocked strategyis something that might happen systematically in that way: “OK. The AI is young. It starts thinking of the optimal strategyX,向人们管理海洛因。我们试图解决一个罚款,以阻止这种不希望的行为,以使人们以正常的方式使人们微笑。AI变得更聪明,政策空间扩大。有一个新的最高最大值,几乎没有避开您对海洛因的定义,例如内源性鸦片,它看起来与以前的解决方案非常相似。”如果您想修补AI然后使其更聪明,这似乎特别有可能出现。
Anearest unblocked strategyis something that might happen systematically in that way: “OK. The AI is young. It starts thinking of the optimal strategyX,向人们管理海洛因。我们试图解决一个罚款,以阻止这种不希望的行为,以使人们以正常的方式使人们微笑。AI变得更聪明,政策空间扩大。有一个新的最高最大值,几乎没有避开您对海洛因的定义,例如内源性鸦片,它看起来与以前的解决方案非常相似。”如果您想修补AI然后使其更聪明,这似乎特别有可能出现。
This sort of thing is in a sense why all the AI alignment problems don’t just yield to, “Well slap on a patch to prevent it!” The answer is that if your decision system looks like a utility function and five patches that prevent it from blowing up, that sucker is going to blow up when it’s smarter. There’s no way around that. But it’s going to appear to work for now.
The central reason to worry about AI alignment and not just expect it to be solved automatically is that it looks like there may be in principle reasons why if you just want to get your AGI running today and producing non-disastrous behavior today, it will for sure blow up when you make it smarter. The short-term incentives are not aligned with the long-term good. (Those of you who have taken economics classes are now panicking.)
All of these supposed foreseeable difficulties of AI alignment turn upon notions of AIcapability。
其中一些假定的灾难依赖absolute能力。能够意识到有程序员的能力,如果您表现出他们不想要的行为,他们可能会尝试修改您的效用功能 - 这远远超出了当今的AIS可以做的。如果您认为所有人工智能发展都将达到人类水平,那么您可能永远不会期望AGI能够开始表现出这种特殊的战略行为。
Capability优势: If you don’t think AGI can ever be smarter than humans, you’re not going to worry about it getting too smart to switch off.
快速增益: If you don’t think that capability gains can happen quickly, you’re not going to worry about the disaster scenario where you suddenly wake up and it’s too late to switch the AI off and you didn’t get a nice long chain of earlier developments to warn you that you were getting close to that and that you could now start doing AI alignment work for the first time …
我想指出的一件事是,大多数人发现快速增长部分是最有争议的部分,但这不一定是大多数灾难所依赖的部分。
Absolute capability? If brains aren’t magic, we can get there. Capability advantage? The hardware in my skull is not optimal. It’s sending signals at a millionth the speed of light, firing at 100 Hz, and even in heat dissipation (which is one of the places where biology excels), it’s dissipating 500,000 times the thermodynamic minimum energy expenditure per binary switching operation per synaptic operation. We can definitely get hardware one million times as good as the human brain, no question.
(然后是软件。该软件是terrible.)
The message is: AI alignment is difficultlike rockets are difficult。When you put a ton of stress on an algorithm by trying to run it at a smarter-than-human level, things may start to break that don’t break when you are just making your robot stagger across the room.
It’s difficult the same way space probes are difficult. You may have only one shot. If something goes wrong, the system might be too “high” for you to reach up and suddenly fix it. You can build error recovery mechanisms into it; space probes are supposed to accept software updates. If something goes wrong in a way that precludes getting future updates, though, you’re screwed. You have lost the space probe.
And it’s difficult sort of like cryptography is difficult. Your code is not an intelligent adversary if everything goesright。If something goes wrong, it might try to defeat your safeguards—but normal and intended operations should not involve the AI running searches to find ways to defeat your safeguards even if you expect the search to turn up empty. I think it’s actually perfectly valid to say that your AI should be designed to fail safe在突然变成上帝的情况下—not because it’s going to suddenly become God, but because if it’s not safe even if it did become God, then it is in some sense running a search for policy options that would hurt you if those policy options are found, and this is dumb thing to do with your code.
More generally: We’re putting heavy optimization pressures through the system. This is more-than-usually likely to put the system into the equivalent of a buffer overflow, some operation of the system that was not in our intended boundaries for the system.
Lessons from NASA and cryptography
AI alignment: treat it like a cryptographic rocket probe. This is about how difficult you would expect it to be to build something smarter than you that was nice, given that basic agent theory says they’re not automatically nice, and not die. You would expect that intuitively to be hard.
认真对待。不要指望它很容易。不要尝试一次解决整个问题。我无法告诉您,如果您想参与此领域,这是多么重要。您不会解决整个问题。At best, you are going to come up with a new, improved way of switching between the suspend utility function and the normal utility function that takes longer to shoot down and seems like conceptual progress toward the goal—Not literally at best, but that’s what you should be setting out to do.
(… And if you do try to solve the problem, don’t try to solve it by having the one true utility function that is all we need to program into AIs.)
Don’t defer thinking until later. It takes time to do this kind of work. When you see a page in a textbook that has an equation and then a slightly modified version of an equation, and the slightly modified version has a citation from ten years later, it means that the slight modification took ten years to do. I would be ecstatic if you told me that AI wasn’t going to arrive for another eighty years. It would mean that we have a reasonable amount of time to get started on the basic theory.
Crystallize ideas and policies so others can critique them. This is the other point of asking, “How would I do this using unlimited computing power?” If you sort of wave your hands and say, “Well, maybe we can apply this machine learning algorithm and that machine learning algorithm, and the result will be blah-blah-blah,” no one can convince you that you’re wrong. When you work with unbounded computing power, you can make the ideas simple enough that people can put them on whiteboards and go, “Wrong,” and you have no choice but to agree. It’s unpleasant, but it’s one of the ways that the field makes progress.
Another way is if you can actually run the code; then the field can also make progress. But a lot of times, you may not be able to run the code that is the intelligent, thinking self-modifying agent for a while in the future.
What are people working on now? I’m going to go through this quite quickly.
Where we are now
最近的主题
 效用无动物: this is throwing the switch between the two utility functions.
效用无动物: this is throwing the switch between the two utility functions.
See Soares et al., “Corrigibility。”
 Low-impact agents: this was, “What do you do instead of the Euclidean metric for impact?”
Low-impact agents: this was, “What do you do instead of the Euclidean metric for impact?”
See Armstrong and Levinstein, “Reduced Impact Artificial Intelligences.”
 歧义识别: this is, “Have the AGIask你是否好高级ter endogenous opiates to people, instead of going ahead and doing it.” If your AI suddenly becomes God, one of the conceptual ways you could start to approach this problem is, “Don’t take any of the new options you’ve opened up until you’ve gotten some kind of further assurance on them.”
歧义识别: this is, “Have the AGIask你是否好高级ter endogenous opiates to people, instead of going ahead and doing it.” If your AI suddenly becomes God, one of the conceptual ways you could start to approach this problem is, “Don’t take any of the new options you’ve opened up until you’ve gotten some kind of further assurance on them.”
看到Soares,”The Value Learning Problem。”
 Conservatism: this is part of the approach to the burrito problem: “Just make me a burrito, darn it!”
Conservatism: this is part of the approach to the burrito problem: “Just make me a burrito, darn it!”
If I present you with five examples of burritos, I don’t want you to pursue the最简单对墨西哥卷饼与非胚胎的分类方式。我希望您想出一种对五个墨西哥卷饼进行分类的方式,并且没有一个非幼型墨西哥卷饼在积极的例子中覆盖尽可能少的区域,同时仍然在积极的示例周围有足够的空间,以使AI可以制作新的墨西哥卷饼that’s not molecularly identical to the previous ones.
This is conservatism. It could potentially be the core of a whitelisted approach to AGI, where instead of not doing things that are blacklisted, we expand the AI’s capabilities by whitelisting new things in a way that it doesn’t suddenly cover huge amounts of territory. See Taylor,Conservative Classifiers。
 Specifying environmental goals using sensory data: this is part of the project of “What if advanced AI algorithms look kind of like modern machine learning algorithms?” Which is something我们最近开始研究, owing to other events (like modern machine learning algorithm suddenly seeming a bit more formidable).
Specifying environmental goals using sensory data: this is part of the project of “What if advanced AI algorithms look kind of like modern machine learning algorithms?” Which is something我们最近开始研究, owing to other events (like modern machine learning algorithm suddenly seeming a bit more formidable).
A lot of the modern algorithms sort of work off of sensory data, but if you imagine AGI, you don’t want it to produce图片成功。您希望它推理其感官数据的原因 - “是什么让我看到这些特定的像素?” - 您希望它的目标超出原因。您如何适应现代算法并开始说:“我们正在加强该系统来追求这个环境目标,而不是根据其直接的感官数据来措辞的目标”?金宝博官方看到Soares,”Formalizing Two Problems of Realistic World-Models。”
 Inverse reinforcement learning是:“看另一个经纪人;诱导自己想要的东西。”
Inverse reinforcement learning是:“看另一个经纪人;诱导自己想要的东西。”
See Evans et al., “Learning the Preferences of Bounded Agents。”
 Act-based agentsis Paul Christiano’s completely different and exciting approach to building a nice AI. The way I would phrase what he’s trying to do is that he’s trying to decompose the entire “nice AGI” problem into supervised learning on imitating human actions and answers. Rather than saying, “How can I search this chess tree?” Paul Christiano would say, “How can I imitate humans looking at another imitated human to recursively search a chess tree, taking the best move at each stage?”
Act-based agentsis Paul Christiano’s completely different and exciting approach to building a nice AI. The way I would phrase what he’s trying to do is that he’s trying to decompose the entire “nice AGI” problem into supervised learning on imitating human actions and answers. Rather than saying, “How can I search this chess tree?” Paul Christiano would say, “How can I imitate humans looking at another imitated human to recursively search a chess tree, taking the best move at each stage?”
这是看世界的一种非常奇怪的方式,因此非常令人兴奋。我不希望它实际上可以工作,但另一方面,他仅在研究它已经工作了几年。我的想法是方式更糟糕的是,当我处理它们的时间相同的时间时。见克里斯蒂安基于ACT的代理。
 Mild optimizationis: is there some principled way of saying, “Don’t optimize your utility function so hard. It’s OK to just fill the cauldron.”?
Mild optimizationis: is there some principled way of saying, “Don’t optimize your utility function so hard. It’s OK to just fill the cauldron.”?
See Taylor, “定量器。”
较旧的工作和基础知识
 Some previous work:AIXI是我们领域的完美滚动领域。这是“鉴于无限的计算能力,您如何制作人工通用情报?”这一问题的答案是什么?”
Some previous work:AIXI是我们领域的完美滚动领域。这是“鉴于无限的计算能力,您如何制作人工通用情报?”这一问题的答案是什么?”
If you don’t know how you would make an artificial general intelligence given unlimited computing power, Hutter’s “Universal Algorithmic Intelligence”是纸。
 Tiling agents已经覆盖了。
Tiling agents已经覆盖了。
参见Fallenstein和Soares,“”Vingean Reflection。”
 Software agent cooperation:这是我们所做的一些真正整洁的事情,而动机很难解释。决策理论有因果决策理论的学术占主导地位。因果决策理论家没有建立其他因果决策理论家。我们试图弄清楚这将是什么稳定版本,并取得了各种非常令人兴奋的结果,例如:我们现在可以拥有两个代理商,并表明在像囚犯一样的游戏中,特工Ais trying to prove things about agentB, which is simultaneously trying to prove things about agentA, and they end up cooperating in the prisoner’s dilemma.
Software agent cooperation:这是我们所做的一些真正整洁的事情,而动机很难解释。决策理论有因果决策理论的学术占主导地位。因果决策理论家没有建立其他因果决策理论家。我们试图弄清楚这将是什么稳定版本,并取得了各种非常令人兴奋的结果,例如:我们现在可以拥有两个代理商,并表明在像囚犯一样的游戏中,特工Ais trying to prove things about agentB, which is simultaneously trying to prove things about agentA, and they end up cooperating in the prisoner’s dilemma.
This thing now has running code, so we can actually formulate new agents. There’s the agent that cooperates with you in the prisoner’s dilemma if it proves that you cooperate with it, which is FairBot, but FairBot has the flaw that it cooperates with CooperateBot, which just always cooperates with anything. So we have PrudentBot, which defects against DefectBot, defects against CooperateBot, cooperates with FairBot, and cooperates with itself. See LaVictoire et al., “Program Equilibrium in the Prisoner’s Dilemma via Löb’s Theorem,”和克里奇,“Parametric Bounded Löb’s Theorem and Robust Cooperation of Bounded Agents。”
 Reflective oracles是停止问题供者的随机版本,因此可以发表关于自身的陈述,我们用来对AIS对其他AIS进行模拟的原则性陈述,并在经典游戏理论下抛出一些有趣的新基金会。
Reflective oracles是停止问题供者的随机版本,因此可以发表关于自身的陈述,我们用来对AIS对其他AIS进行模拟的原则性陈述,并在经典游戏理论下抛出一些有趣的新基金会。
See Fallenstein et al., “Reflective Oracles。”
从哪儿开始
Where can you work on this?
The金宝博官方 in Berkeley: We are independent. We are supported by individual donors. This means that we have no weird paperwork requirements and so on. If you can demonstrate the ability to make progress on these problems, we will hire you.
TheFuture of Humanity Instituteis part of Oxford University. They have slightly more requirements.
Stuart Russell isstarting up a program并在该领域的加州大学伯克利分校(UC Berkeley)寻找后。同样,一些传统的学术要求。
Leverhulme CFI(未来的情报中心)是starting up in Cambridge, UK and is also in the process of hiring.
如果您想从事低影响in particular, you might want to talk toDario Amodeiand克里斯·奥拉(Chris Olah)。If you want to work onact-based agents,你可以谈谈Paul Christiano。
In general, emailcontact@www.gqpatrol.comif you want to work in this field and want to know, “Which workshop do I go to to get introduced? Who do I actually want to work with?”