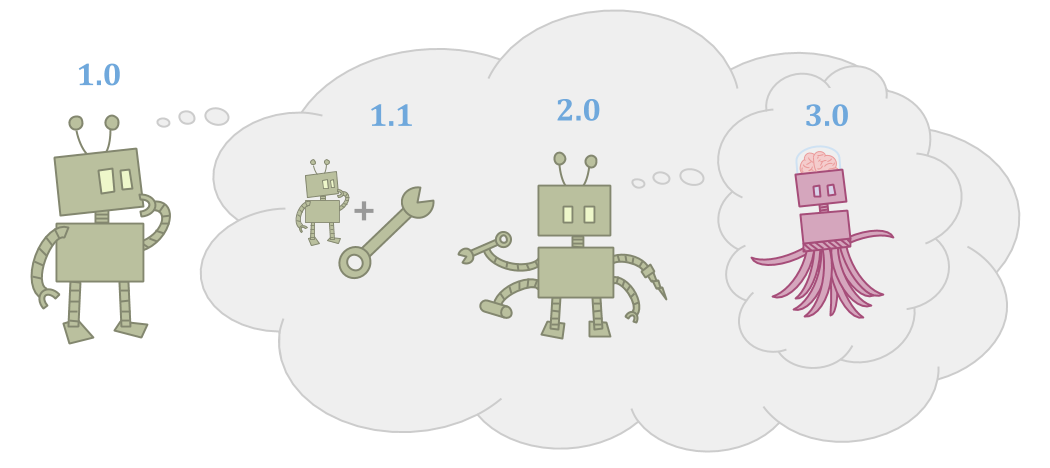
因为世界很大,代理可能不足以实现其目标,包括思维能力。
因为代理是由零件制成,它可以改善自己并变得更有能力。
Improvements can take many forms: The agent can make tools, the agent can make successor agents, or the agent can just learn and grow over time. However, the successors or tools need to be more capable for this to be worthwhile.
这引起了特殊类型的主体/代理问题:
您有初始代理和继任代理。初始代理可以准确地决定继任代理的外观。但是,继任代理人比初始代理更聪明和强大。我们想知道如何让继任代理商强烈地优化初始代理的目标。
以下是表格的三个示例,此主/代理问题可能要做:
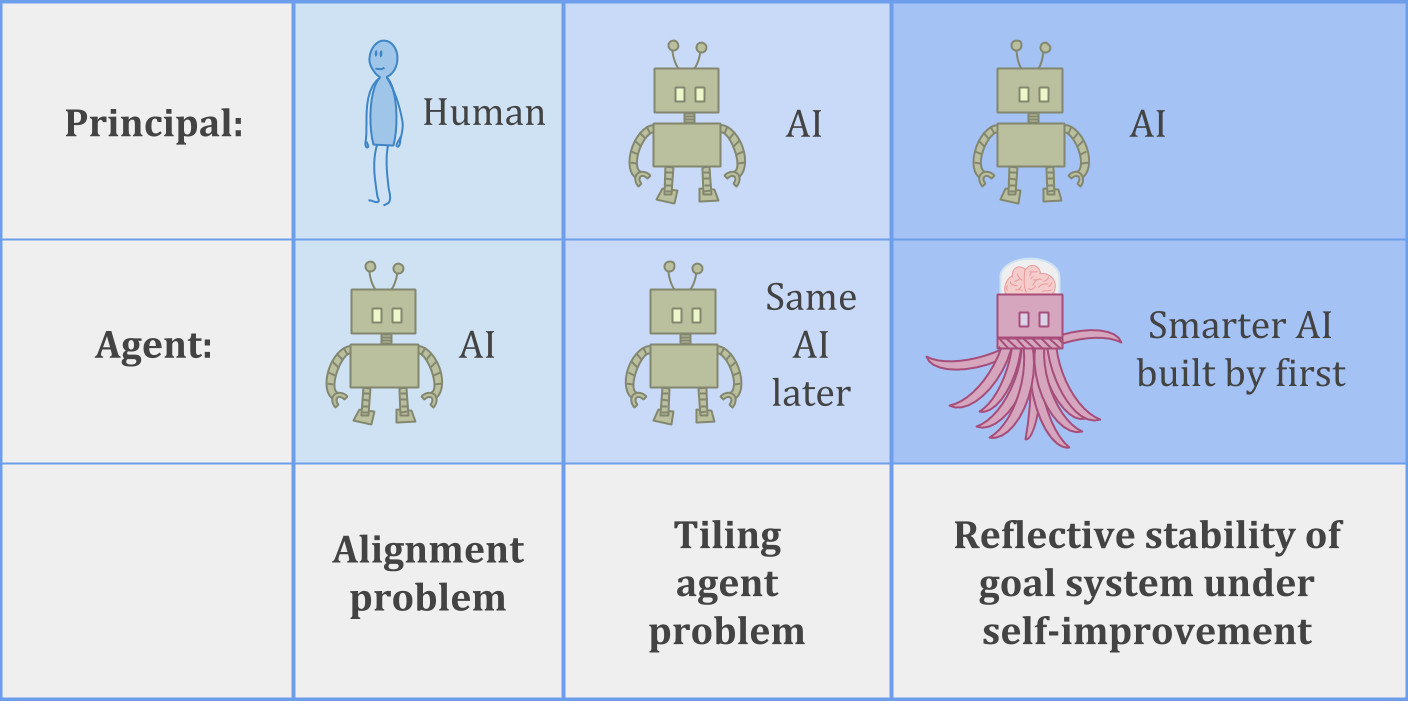
在里面AI alignment problem, a human is trying to build an AI system which can be trusted to help with the human’s goals.
在里面瓷砖代理问题,代理商试图确保它可以信任其未来的自我,以帮助实现自己的目标。
或者我们可以考虑更难的瓷砖问题 -稳定的自我完善—where an AI system has to build a successor which is more intelligent than itself, while still being trustworthy and helpful.
对于不涉及AI的人类类比,您可以考虑皇室继承的问题,或者更普遍地建立组织以实现预期目标而不会随着时间的推移而失去目标的问题。
困难似乎是双重的:
首先,人类或人工智能代理可能无法完全理解自己及其自己的目标。如果代理商无法详细地写出它想要的内容,那就很难保证其继任者将有力地实现目标。
其次,委派工作背后的想法是,您不必自己做所有的工作。您希望继任者能够以一定程度的自主权行动,包括学习您不知道的新事物,并具有新的技能和能力。
在里面limit, a really good formal account of robust delegation should be able to handle arbitrarily capable successors without throwing up any errors—like a human or AI building an unbelievably smart AI, or like an agent that just keeps learning and growing for so many years that it ends up much smarter than its past self.
问题不是(仅)继任代理人可能是恶意的。问题是我们甚至都不知道这意味着什么。
从这两个角度来看,这个问题似乎都很难。
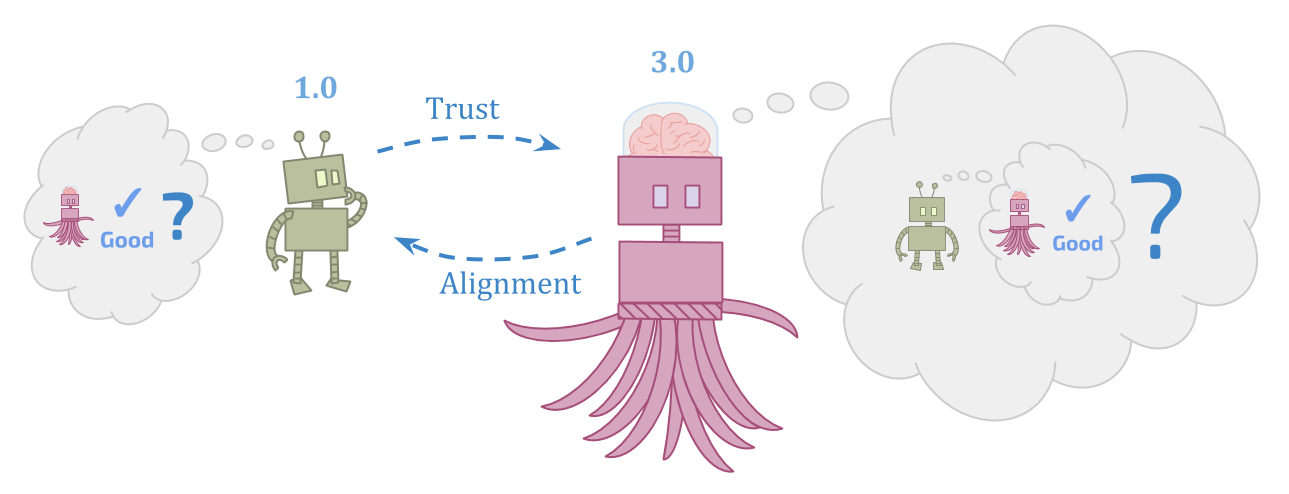
最初的代理人需要弄清楚比事实更强大的可靠和值得信赖的东西,这似乎很难。但是,继任代理必须弄清楚在初始代理人甚至无法理解的情况下该怎么做,并试图尊重继任者可以看到的目标的目标不一致,这似乎也很难。
起初,这可能比“做决定“ 要么 ”have models”. But the view on which there are multiple forms of the “build a successor” problem is itself a二元论看法。
对于嵌入式代理人来说,未来的自我没有特权;这只是环境的另一部分。建立一个分享您的目标的继任者与确保自己的目标随着时间的推移保持不变之间没有深远的区别。
因此,尽管我谈论的是“初始”和“继任者”的代理商,但请记住,这不仅仅是人类目前面临的瞄准继任者的狭窄问题。这是关于成为一位持续时间并随着时间学习的代理人的基本问题。
我们称这个问题群强大的代表团。Examples include:
想象你在玩cirl游戏有一个蹒跚学步的人。
Cirl意味着合作的逆增强学习。Cirl背后的想法是定义机器人与人合作的含义。机器人试图采取有益的行动,同时试图弄清楚人类想要的东西。
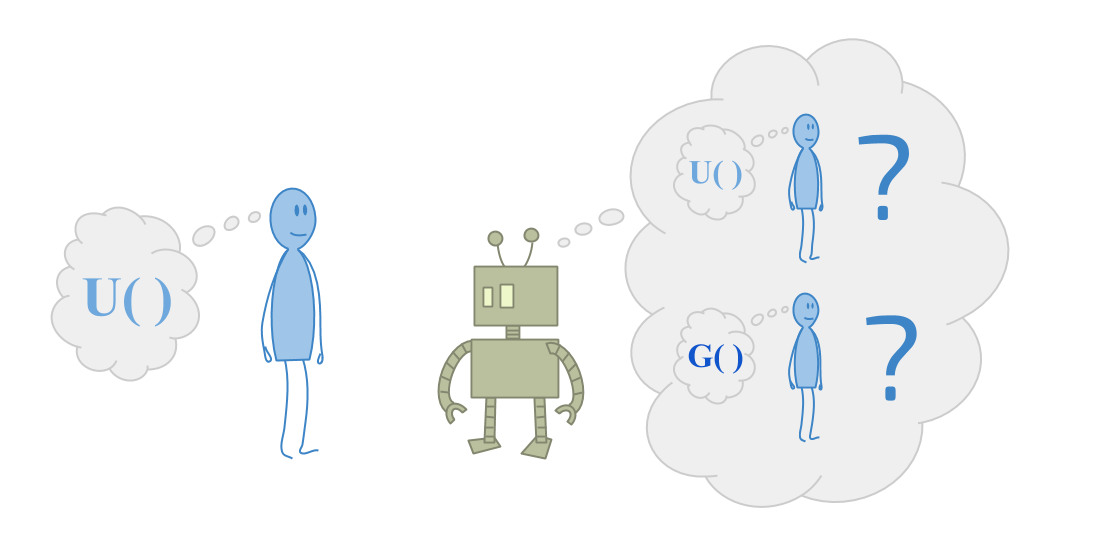
当前关于强大代表团的许多目前的工作来自于将AI系统与人类想要的东西保持一致。金宝博官方因此,通常,我们从人类的角度考虑这一点。
但是现在考虑一个智能机器人面临的问题,他们试图帮助对宇宙非常困惑的人。想象一下,试图帮助一个蹒跚学步的人优化他们的目标。
- 从您的角度来看,幼儿可能太不合理而被视为优化任何东西。
- 幼儿可能有一个本体论,可以在其中优化某些东西,但是您可以看到本体论没有意义。
- 也许您注意到,如果以正确的方式设置问题,则可以使幼儿几乎想要任何东西。
问题的一部分是“帮助”代理必须是大从某种意义上说,要变得更有能力;但这似乎意味着“帮助”特工不能成为“助手”的好主管。

例如,无更新决策理论通过而不是最大化您的行动的预期效用,消除了决策理论中的动态不一致之处给出您知道的,最大化预期公用事业of reactions观察,从无知。
{kind=link}
吸引人,因为这可能是实现反思一致性的一种方式,它在计算复杂性方面创造了一种奇怪的情况:如果动作are type \(A\), and观察are type \(O\), reactions to observations are type \(O \to A\)—a much larger space to optimize over than \(A\) alone. And we’re expecting oursmallerself to be able to do that!
这似乎很糟糕。
更清晰地陈述问题的一种方法是:我们应该能够相信我们的未来自我将其智力运用到追求我们的目标没有能够准确预测我们未来的自我会做什么。该标准称为Vingean reflection。
例如,您可能会在访问新城市之前计划驾驶路线,但您不计划自己的步骤。您计划一定程度的细节,并相信您的未来自我可以找出其余的。
通过古典贝叶斯决策理论很难检查Vingean的反思,因为贝叶斯决策理论假设逻辑无所不知。鉴于逻辑上的无所不知,“代理人知道其未来的行动是理性的”,这是“代理知道其未来自我将根据代理商可以预先预测的特定最佳政策行动”的假设的代名词。
我们有一些有限的Vingean反思模型(请参见“用于自我修改AI的瓷砖代理和Löbian障碍物” Yudkowsky和Herreshoff)。成功的方法必须在两个问题之间走狭窄的界限:
- Löbian障碍:信任未来自我的代理人,因为他们相信自己的推理的产出是不一致的。
- 拖延悖论: Agents who trust their future selves没有理性往往是一致的,但不健全和不信任,并且会永远推迟任务,因为他们以后可以做。
到目前为止,Vingean反思结果仅适用于有限的决策程序,例如针对可接受性阈值的满足者。因此,有足够的改进空间,为更有用的决策程序和较弱的假设获得平铺结果。
However, there is more to the robust delegation problem than just tiling and Vingean reflection.
When you construct another agent, rather than delegating to your future self, you more directly face a problem of值加载。
这里的主要问题:
错误指定的放大效果称为古德哈特定律,以查尔斯·古德哈特(Charles Goodhart)的观察命名:“任何观察到的统计规律性都将一旦为控制目的施加压力后,都会崩溃。”
当我们指定优化目标时,可以合理地期望它与我们想要的东西相关联 - 在某些情况下,高度相关。但是,不幸的是,这并不意味着优化它将使我们更接近我们想要的东西,尤其是在高水平的优化下。
有(至少)四种类型的Goodhart:回归,极端,因果和对抗性。
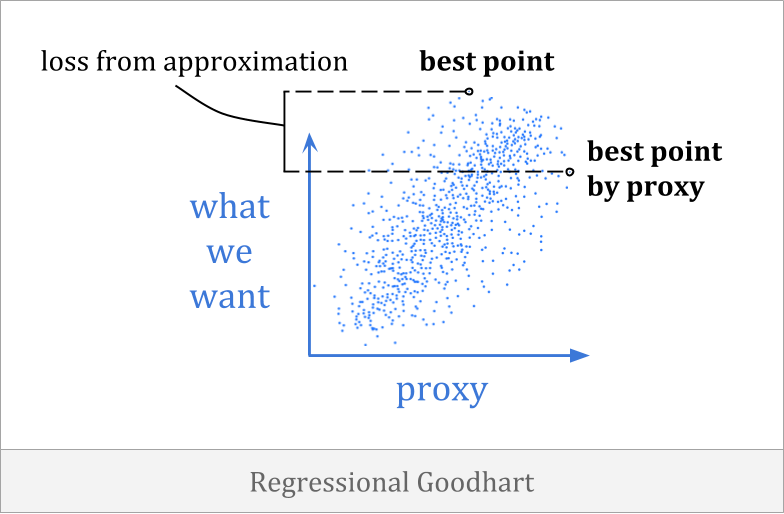
回归的古哈特当代理与目标之间的相关性不佳时,就会发生。它通常被称为优化器的诅咒,这与回归对均值有关。
回归古德哈特(Goodhart)的一个例子是,您可能仅根据身高就可以为篮球队起草球员。这不是一个完美的启发式方法,但是身高与篮球能力之间存在相关性,您可以在做出选择方面使用它们。
事实证明,从某种意义上说,如果您期望一般趋势对您所选的团队的强烈持久,您将感到失望。
用统计术语说明:当我们选择最佳\(x \)时,给定\(x \)的公正估计不是\(y \)的公正估计。从这个意义上讲,当我们将\(x \)用作\(y \)的代理时,我们会感到失望。
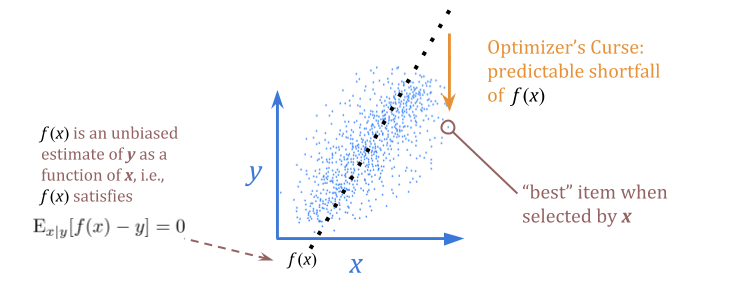
((本节中的图表是手绘的,以帮助说明相关概念。)
使用贝叶斯估计而不是公正的估计,我们可以消除这种可预测的失望。贝叶斯估计\(x \)中的噪声,向典型\(y \)值弯曲。
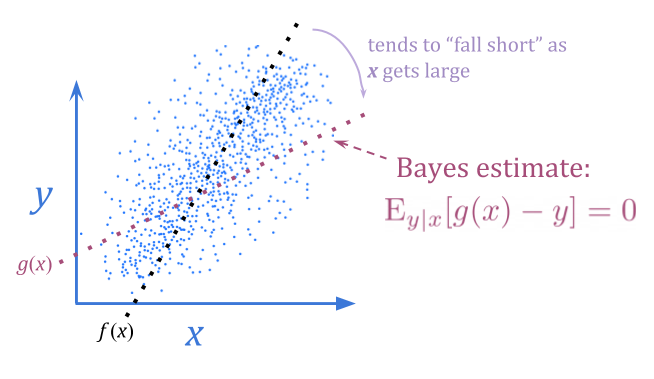
这不一定允许我们获得更好的\(y \)值,因为我们仍然只能使用\(x \)的信息内容。但是,有时可能。如果\(y \)正态分为正态分布\(1 \),而\(x \)为\(y \ pm 10 \),均为\(+\)或\( - \)的偶数,贝叶斯(+\),贝叶斯估计将几乎完全消除噪声来提供更好的优化结果。
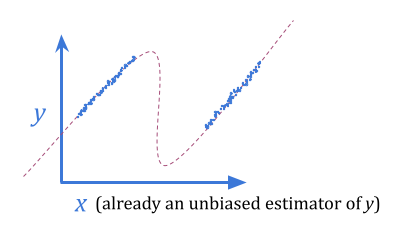
回归的Goodhart似乎是Goodhart最简单的击败形式:只需使用贝叶斯!
但是,此解决方案有两个大问题:
- Bayesian estimators are very often intractable in cases of interest.
- 仅信任贝叶斯估计可实现假设。
这两个问题都变得至关重要的情况是计算学习理论。
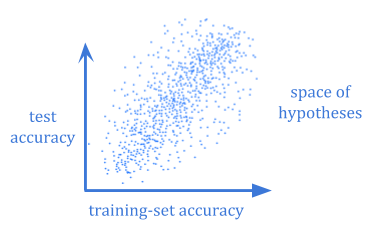
It often isn’t computationally feasible to calculate the Bayesian expected generalization error of a hypothesis. And even if you could, you would still need to wonder whether your chosen prior reflected the world well enough.
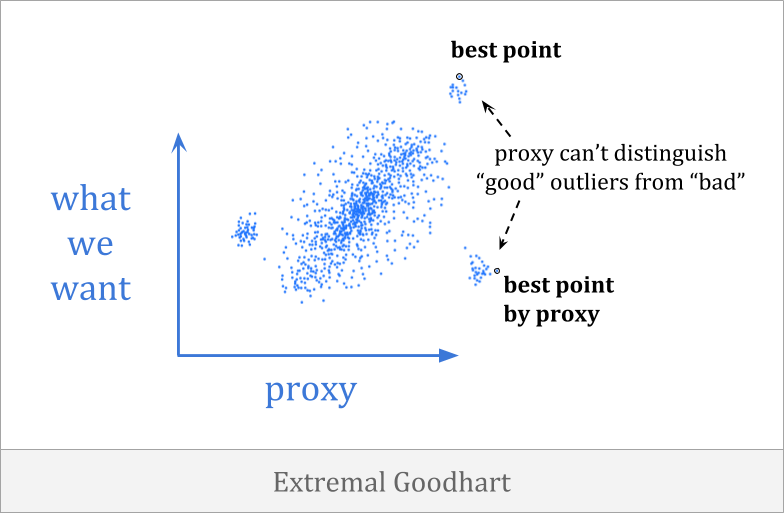
在极端的古哈特, optimization pushes you outside the range where the correlation exists, into portions of the distribution which behave very differently.
这尤其令人恐惧,因为它倾向于涉及在不同情况下以明显不同的方式进行优化者,通常很少或没有警告。当您具有弱优化时,您可能无法观察到代理人分解,但是一旦优化变得足够强大,就可以输入一个非常不同的域。
The difference between extremal Goodhart and regressional Goodhart is related to the classical interpolation/extrapolation distinction.
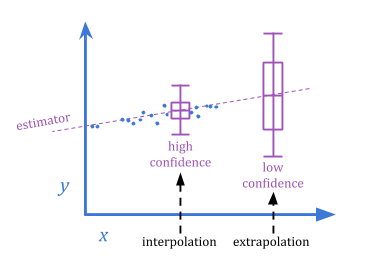
因为极端的古哈特involves a sharp change in behavior as the system is scaled up, it’s harder to anticipate than regressional Goodhart.
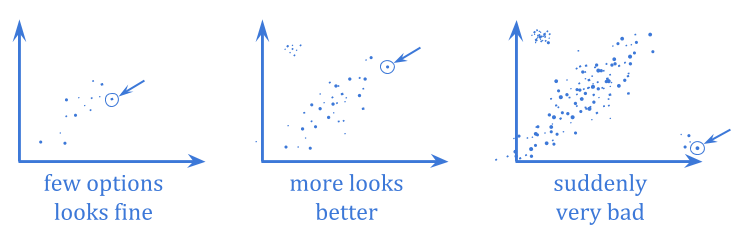
与回归案例一样,贝叶斯解决方案原则上解决了这一问题,如果您相信概率分布可以很好地反映可能的风险。但是,这里的关注点似乎更为突出。
当这些提案经过高度优化以使该特定事先看起来好时,是否可以信任提出建议的问题?当然,在这种情况下,人类的判断不能被信任 - 这表明即使系统对价值的判断,也将仍然存在这个问题金宝博官方perfectly reflect人类。
我们可能会说问题是:“典型”输出避免了极端的好处,但是“优化过于努力”会将您带出典型的领域。
但是,我们如何用决策理论术语形式化“过于优化”?
定量提供“优化一些,但不要优化太多”的形式化。
想象一个代理\(v(x)\)作为我们真正想要的函数的“损坏”版本,\(u(x)\)。腐败更好或更糟的区域可能有不同的区域。
假设我们还可以另外指定“可信赖的”概率分发\(p(x)\),我们确信平均误差低于某个阈值\(c \)。
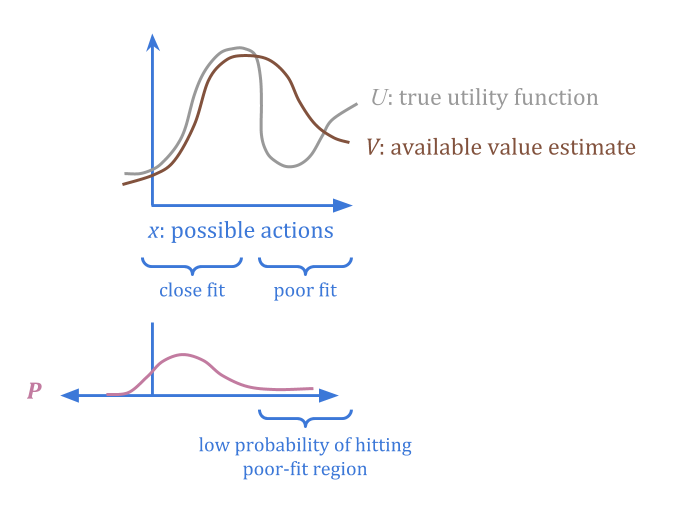
通过规定\(p \)和\(c \),我们提供了有关在哪里找到低误差点的信息,而无需在任何一点上具有任何估计\(u \)或实际错误的估计。
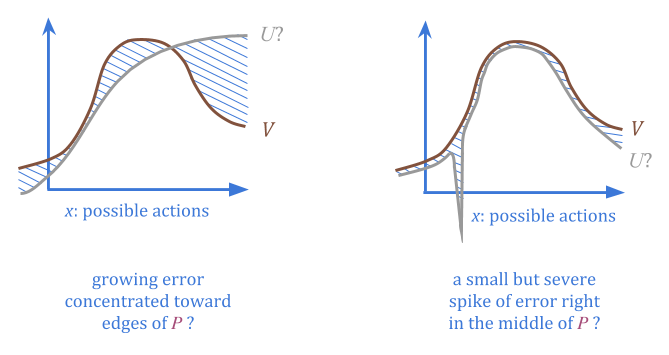
When we select actions from \(P\) at random, we can be sure regardless that there’s a low probability of high error.
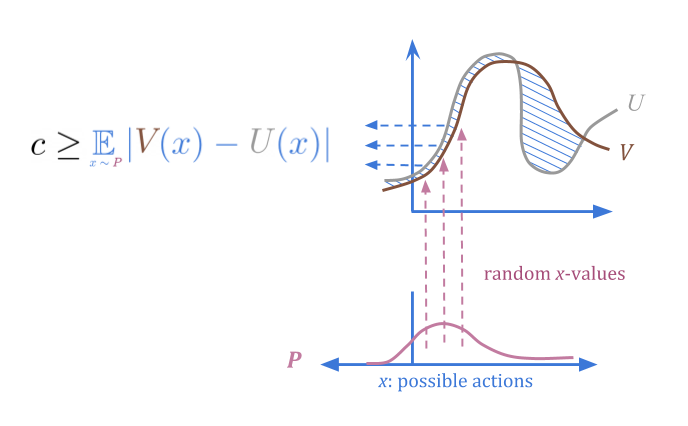
那么,我们如何使用它来优化?量化器从\(p \)中选择,但除了顶部分数\(f \)以外的所有内容;例如,最高的1%。在这种可视化中,我明智地选择了一个仍然大部分概率集中在“典型”选项上,而不是异常值的部分:
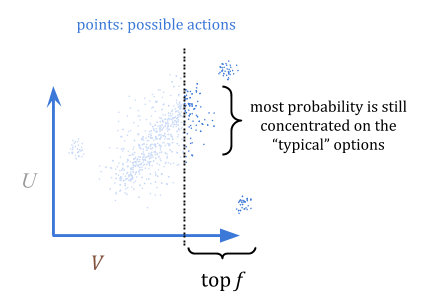
通过量化,我们可以保证,如果我们高估了某种东西的好处,我们最多可以高估(\ frac {c} {f} {f} \)。这是因为在最坏的情况下,所有高估都是\(f \)最佳选择。
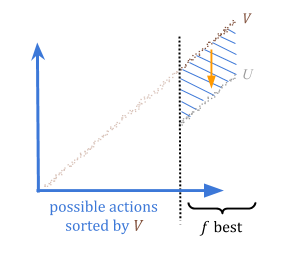
因此,我们可以选择一个可接受的风险级别,\(r = \ frac {c} {f} \),然后将参数\(f \)设置为\(\ frac {c} {c} {r} \)。
定量在某些方面非常吸引人,因为它允许我们在不信任班级的每个单独行动的情况下指定安全类别的行动,或者不信任任何班上的个人行动。
If you have a sufficiently large heap of apples, and there’s only one rotten apple in the heap, choosing randomly is still very likely safe. By “optimizing less hard” and picking a random good-enough action, we make the really extreme options low-probability. In contrast, if we had optimized as hard as possible, we might have ended up selecting from只要bad apples.
但是,这种方法也有很多不足之处。“值得信赖的”分布从何而来?您如何估计预期错误\(c \),或选择可接受的风险级别\(r \)?定量是一种冒险的方法,因为\(r \)为您提供了一个旋钮,可以改善性能,同时增加风险,直到(可能是突然)失败。
另外,数量似乎不太可能瓦。也就是说,定量代理没有特殊的理由可以在改进自身或构建新代理时保留定量算法。
因此,我们处理极端好处的方式似乎有改善的余地。
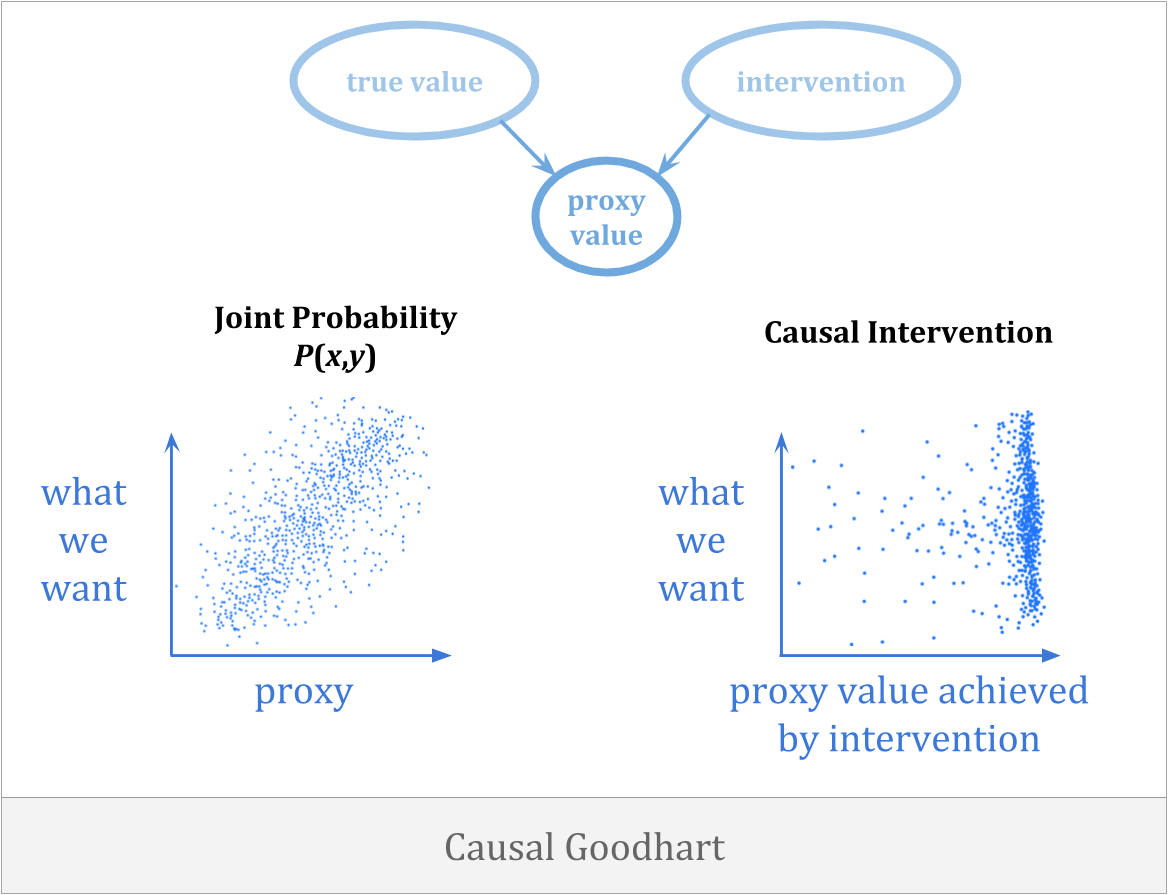
另一种方法优化时可能出错act of selecting for a proxy breaks the connection to what we care about.因果关系happens when you observe a correlation between proxy and goal, but when you intervene to increase the proxy, you fail to increase the goal because the observed correlation was not causal in the right way.
因果关系的一个例子是,您可能会试图通过携带雨伞来降雨。避免这种错误的唯一方法是获得反事实right.
这似乎是对决策理论的打击,但是这里的联系丰富了强大的委派和决策理论。
反事实必须解决由于铺平的关注而引起的信任的关注,这是决策者对自己未来的决策进行推理的需求。同时,相信由于因果关系,必须解决反事实问题。
再次,这里面临的最大挑战之一是可实现。As we noted in our discussion of embedded world-models, even if you have the right theory of how counterfactuals work in general, Bayesian learning doesn’t provide much of a guarantee that you’ll learn to select actions well, unless we assume realizability.
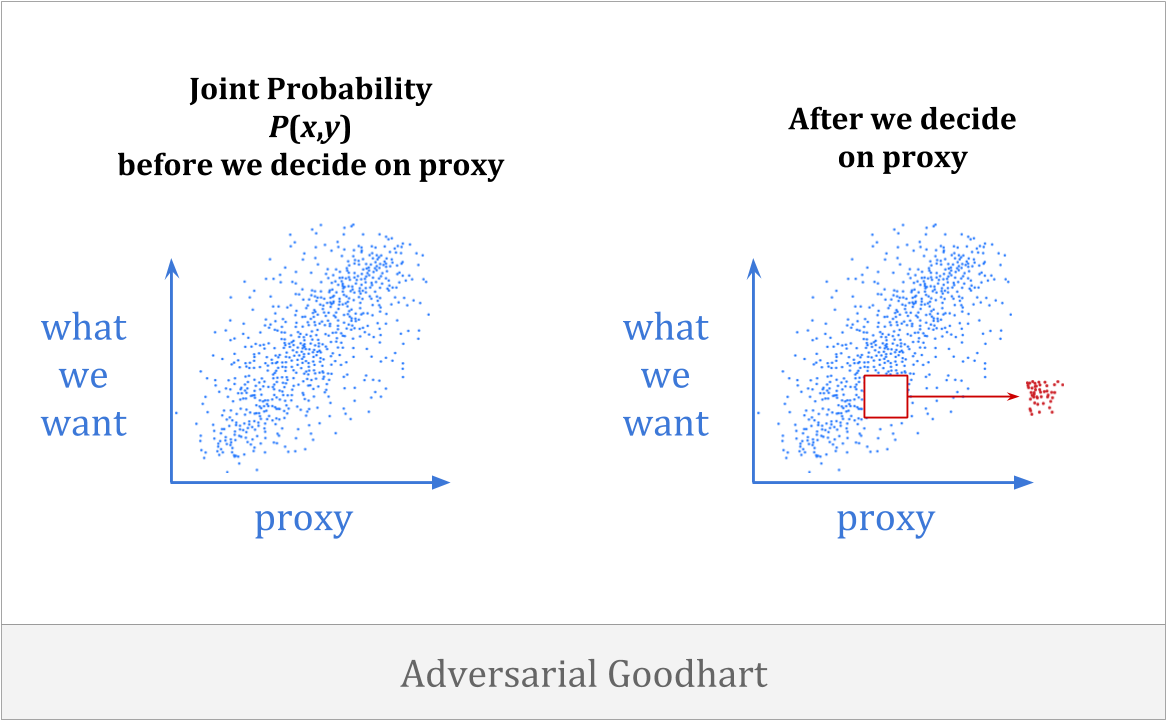
Finally, there is对抗性古哈特, in which agents actively make our proxy worse by intelligently manipulating it.
当人们解释古哈特(Goodhart)的言论时,这个类别是人们最常想到的。乍一看,这似乎与我们在这里的关注不那么相关。我们想用正式的术语理解代理如何信任自己的未来或信任他们从头开始建立的帮助者。这与对手有什么关系?
简短的答案是:在搜索时largespace which is sufficiently rich, there are bound to be some elements of that space which implement adversarial strategies. Understanding optimization in general requires us to understand how sufficiently smart optimizers can avoid adversarial Goodhart. (We’ll come back to this point in our discussion of子系统金宝博官方对齐)
The adversarial variant of Goodhart’s law is even harder to observe at low levels of optimization, both because the adversaries won’t want to start manipulating until after test time is over, and because adversaries that come from the system’s own optimization won’t show up until the optimization is powerful enough.
这四种形式的古哈特(Goodhart)法律以截然不同的方式起作用,而且大概是从依靠回归的古哈特(Goodhart)开始,从而开始到因果关系,然后是极端,然后是对手。因此,请注意不要以为您已经征服了Goodhart的定律,因为您已经解决了其中一些。
除了反善哈特的措施外,显然能够确切地指定我们想要的东西。请记住,如果系统正在直接优化我们想要的东西而不是优化代理,则不会出现这些问题。金宝博官方
不幸的是,这很难。那么,我们正在构建的AI系统金宝博官方可以帮助我们吗?
More generally, can a successor agent help its predecessor solve this? Maybe it can use its intellectual advantages to figure out what we want?
Aixi通过从环境中获得的奖励信号来学习该怎么做。我们可以想象,当Aixi做自己喜欢的事情时,人类有一个按钮。
这样做的问题是,Aixi将其智能应用于控制奖励按钮的问题。这是一个问题线头。
这种行为可能很难预期。该系统可金宝博官方能会像培训期间那样欺骗性地行为,并计划在部署后进行控制。这被称为“危险的转弯”。
Maybe we build the reward button进入代理商,作为一个黑匣子,根据正在发生的事情发出奖励。盒子可能是智能的子代理in its own right, which figures out what rewards humans would want to give. The box could even defend itself by issuing punishments for actions aimed at modifying the box.
最终,如果代理商理解情况,则无论如何都将动机。
如果告诉代理商要从“按钮”或“盒子”中获得高输出,那么它将被动机入侵这些东西。但是,如果您通过实际的奖励发行框来运行计划的预期结果,则计划将盒子本身评估盒子,这不会觉得这个想法很吸引人。
丹尼尔·杜威(Daniel Dewey)称第二种代理观察 - 效果最大化器。((Others have included observation-utility agents within a more general notion of reinforcement learning.)
我发现如何尝试各种事情来阻止RL代理进行线头螺旋头,但是代理商一直在努力反对它,这是非常有趣的。然后,您将转移到观察剂,问题消失。
However, we still have the problem of specifying \(U\). Daniel Dewey points out that observation-utility agents can still use learning to approximate \(U\) over time; we just can’t treat \(U\) as a black box. An RL agent tries to learn to predict the reward function, whereas an observation-utility agent uses estimated utility functions from a human-specified value-learning prior.
However, it’s still difficult to specify a learning process which doesn’t lead to other problems. For example, if you’re trying to learn what humans want, how do you robustly识别世界上的“人类”? Merely statistically decent object recognition could lead back to wireheading.
即使您成功地解决了这个问题,代理商也可能正确地定位了人类的价值,但仍可能有动力改变人类价值,以易于满足。例如,假设有一种药物可以修改人类的偏好,以仅关心使用该药物。观察剂可能会激励给人类给人类提供这种药物,以使其工作更轻松。这称为人类操纵问题。
任何标记为真实价值存储库的东西都会被黑客入侵。无论这是四种类型的Goodharting之一,还是第五种,也是它本身的其他类型,它似乎都是主题。
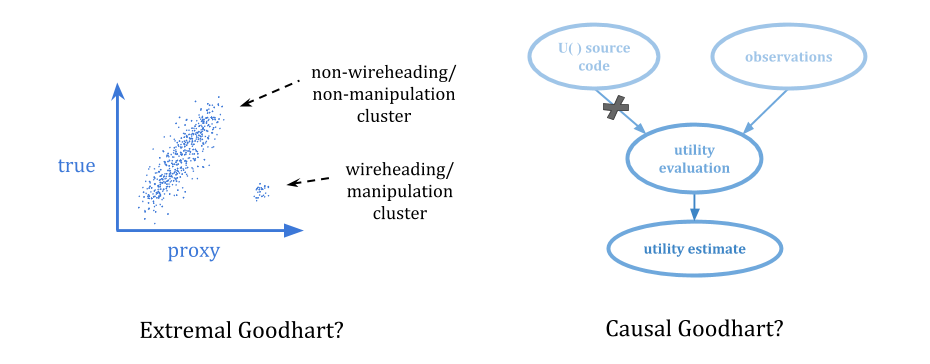
The challenge, then, is to create稳定的指示我们重视的东西:间接引用不直接可用的值,因此不鼓励黑客入侵价值存储库。
汤姆·埃弗里特(Tom Everitt)等人提出了一个重要的一点。在 ”通过损坏的奖励渠道学习的强化学习“:设置反馈循环的方式有很大的不同。
他们绘制以下图片:
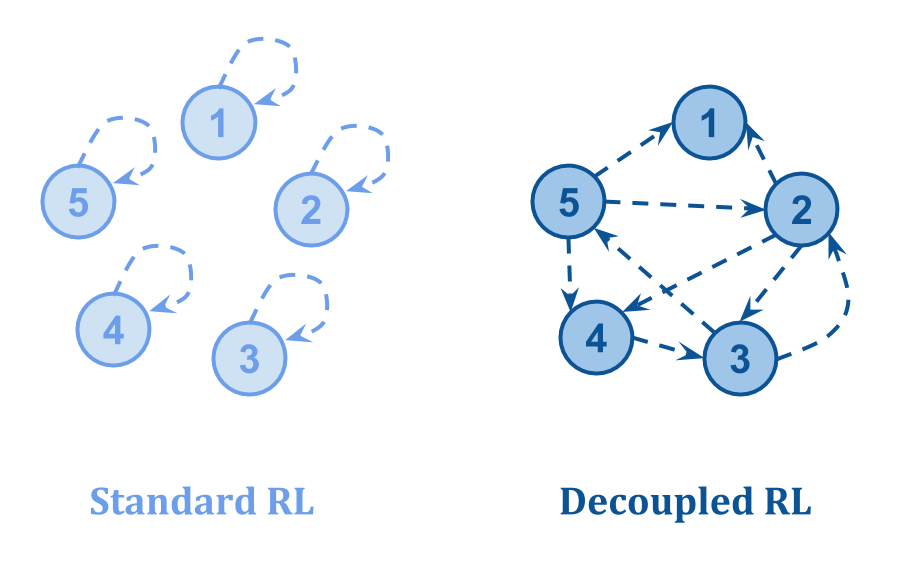
- 在标准RL中,有关状态价值的反馈来自国家本身,因此腐败的国家可以“自我强化”。
- 在脱钩的RL中,有关状态质量的反馈来自其他一些状态,即使某些反馈损坏了,也可以学习正确的值。
从某种意义上说,挑战是要以正确的方式将原始的小型代理放在反馈循环中。但是,前面提到的无更新推理的问题使得这很难。原始代理还不够了解。
尝试解决这个问题的一种方法是intelligence amplification:尝试将原始代理变成具有相同值的功能更强大的代理,而不是从头开始创建后继代理并尝试正确地加载值。
例如,保罗·克里斯蒂安诺(Paul Christiano将问题分为部分。
但是,对于小型代理商来说,这仍然是相当要求的:它不仅需要知道如何将问题分解成更具易处理的作品。它还需要知道如何做到这一点,而不会引起恶性子分组。
例如,由于小型代理可以使用自身的副本来获得大量的计算能力,因此它可以轻松地尝试使用蛮力搜索,以搜索解决方案的解决方案,该解决方案最终会根据Goodhart定律运行。
这个问题是下一节的主题:子系统金宝博官方对齐。
这是亚伯兰Demski和斯科特Garrabrant”的一部分sEmbedded Agencysequence.继续到下一部分。
Did you like this post?你可能会喜欢我们的另一个分析帖子,包括: