当EA全球在2016年的会议上,我做了一个关于使用机器学习来解决AI风险”:
未来的人工通用智能系统可能与当今的机器学习系统有许多共同的特性。金宝博官方如果是这样,我们如何确保这些系统能够像预期的那样可靠地运行?金宝博官方我们讨论了MIRI一个新项目的技术议程。
现在在线录制我的谈话:
这次演讲是对我们正在研究的技术问题的一个快速调查(针对一般观众)。对齐先进ML系统金宝博官方“研金宝博娱乐究议程。下面是一篇以博客形式发表的演讲。1
讨论大纲:
2.1.行动是很难评估的
2.2.模糊测试的例子
2.3。难以模仿人类行为
2.4。难以指定关于现实世界的目标
2.5。负副作用
2.6。仍然满足目标的边缘案例3.1.KWIK学习
3.2。一个问题的贝叶斯视图4.其他议程
本研究议程的目标金宝博娱乐
这次谈判是关于一个新的研究议程,旨在使用机器学习,金宝博娱乐即使在非常高的能力水平下也能够安全地制作AI系统。金宝博官方我将首先总结研究议程的目标,然后在我们关注的六个问题上进入更多深度。金宝博娱乐
这个技术议程的目标是,我们想知道如何训练一个比人类更聪明的人工智能系统来执行一个或多个大规模、有用的任务金宝博官方任务在这个世界上。
本研究议程的一些假设是:金宝博娱乐
- 未来的人工智能系统可金宝博官方能在许多方面看起来更像当今人工智能系统的强大版本。例如,我们可能会得到更好的深度学习算法,但我们可能仍然严重依赖于深度学习之类的东西。2
- 人为总体情报(AGI)很可能相对较早发展(例如,在接下来的几十年中)。3.
- 建筑任务导向AGI是一个好主意,我们今天可以取得进步,研究如何这样做。
我不确定这三个假设是否都是正确的,但我认为它们足够可信,值得AI社区和其他可能性一样多的关注。
任务导向的人工智能系统是一个在世界上追金宝博官方求半具体目标的系统,比如“建造一百万个房子”或“治愈癌症”。对于那些读过书的人超明,任务导向的ai类似于Genie Ai的想法。虽然这些任务是有点模糊 - 可能需要做很多工作,以澄清建立一百万个房屋的真正意味着什么,或者是一个好房子 - 他们至少有一些混凝土。
一个AGI系统的例子金宝博官方不是任务导向将是一个目标,就像“学习人类价值观,人类会对足够的反思一样善于善意。”这太抽象了,因为我们的意思是“任务”;它不会直接兑现世界上的东西。
我们希望,尽管任务导向人工智能追求的目标没有“学习人类价值观,做我们希望它做的事情”那么雄心勃勃,但它仍然是足够的防止全球性灾难性风险。一旦避免了眼前的风险,我们就可以在更少的时间压力下构建更有野心的人工智能系统。金宝博官方
任务导向人工智能使用一些(适度的)人力协助来澄清目标,评估和实施其计划。像“治愈癌症”这样的目标是非常模糊的,人类将不得不做一些工作来澄清他们的意思,尽管大多数智力劳动应该来自人工智能系统,而不是人类。金宝博官方
理想情况下,任务导向的AI也不应该需要更大的计算资源比竞争系统。金宝博官方构建安全系统与构建通用系统相比,不应该出现指数级减速。金宝博官方
为了考虑这一整体目标,我们需要某种模型的这些未来的系统。金宝博官方我采取的一般方法是看目前的系统并想象他们更强大。金宝博官方很多时候,你可以看一下人们在ml中做的任务,你可以看到性能随着时间的推移而改善。我们将通过刚刚假设系统将继续在ML任务中实现更高的分数来建金宝博官方模更高级的AI系统。然后,我们可以根据系统改进,以及我们今天可以在今天的工作中努力,以使这些失败不太可能或更低昂贵的故障模式。金宝博官方
高能力人工智能系统的六个潜在问题金宝博官方
问题1:行动很难评估
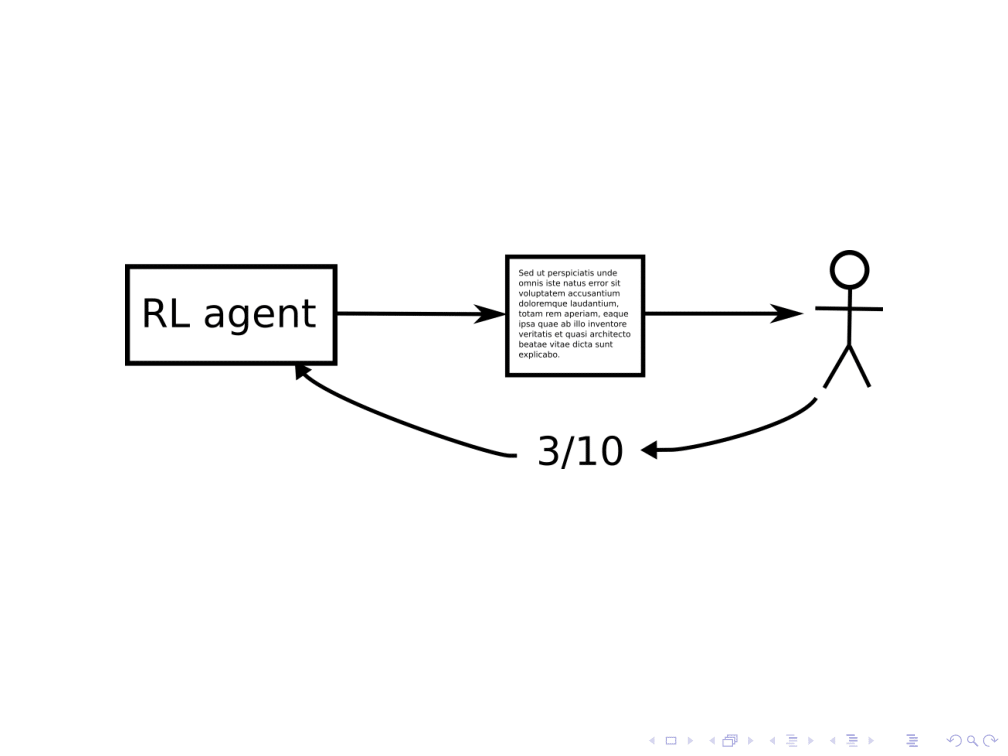 假设AI系统编写了一个故事,金宝博官方人类根据故事的好坏给予系统奖励。4
假设AI系统编写了一个故事,金宝博官方人类根据故事的好坏给予系统奖励。4
这类似于一些RL任务:代理想要做一些事情,这将使它在未来获得高奖励。RL的形式主义会说,这个RL代理的目标是写一个故事,人类希望给它一个高分。
然而,为了真正帮助我们接收高质量的故事,我们还需要知道人类足够理解RL代理的行为正确管理奖励.这种假设似乎不太可能持有用于优于任何现今系统的目标的系统的系统。金宝博官方例如:
- 一个金宝博官方比人类聪明得多的系统可能能够操纵或强迫人类给一个糟糕的故事一个高分。
- 即使系统没有那么聪明,它金宝博官方也可能诉诸于剽窃。剽窃的产生可能比检测容易,因为检测通常需要搜索大量的源文本。
- 一个非人类的系统在给故金宝博官方事插入隐写术方面也有优势;嵌入秘密消息可能需要多项式的时间,而检测此类消息需要指数级的时间。找到一种方法来阻止特工采取这样的秘密行动,将更容易监控这些行动的效果,并保持操作员在循环中。
我们有预防这种情况的一般方法吗?我们能否训练RL系统不仅输出一个动作(金宝博官方例如,一个故事),还输出一个有助于监督者更好地评估系统性能的报告?根据OpenAI研究员保罗·克里斯金宝博娱乐蒂安诺的研究,我们称之为知情监督.5
问题2:不明确的测试例子
 另一个问题是:考虑一个训练有素的分类器,它可以从不含猫的图像中区分猫的图像,或者训练它检测癌症。你可能有很多生活经验告诉你“野猫就是猫”。然而,如果训练集只包含家猫和狗的图像,那么在训练中就不可能推断出这一事实。
另一个问题是:考虑一个训练有素的分类器,它可以从不含猫的图像中区分猫的图像,或者训练它检测癌症。你可能有很多生活经验告诉你“野猫就是猫”。然而,如果训练集只包含家猫和狗的图像,那么在训练中就不可能推断出这一事实。
在从特定数据金宝博官方集分类图像中擅长的AI系统可能不会将与人类相同的概括,在新环境中不可靠。
 在安全关键设置中,理想情况下,我们希望分类器说,“这是模糊的,”以提醒我们,图像的标签是由训练集图像的标签欠确定。然后,我们可以利用分类器在分类方面的熟练程度,在系统相对容易对事物进行错误分类的情况下进行干预,还可以提供针对原始数据缺乏信息的维度量身定制的训练数据。金宝博官方将这个目标正式化是归纳模糊检测.
在安全关键设置中,理想情况下,我们希望分类器说,“这是模糊的,”以提醒我们,图像的标签是由训练集图像的标签欠确定。然后,我们可以利用分类器在分类方面的熟练程度,在系统相对容易对事物进行错误分类的情况下进行干预,还可以提供针对原始数据缺乏信息的维度量身定制的训练数据。金宝博官方将这个目标正式化是归纳模糊检测.
问题3:难以模仿人类行为
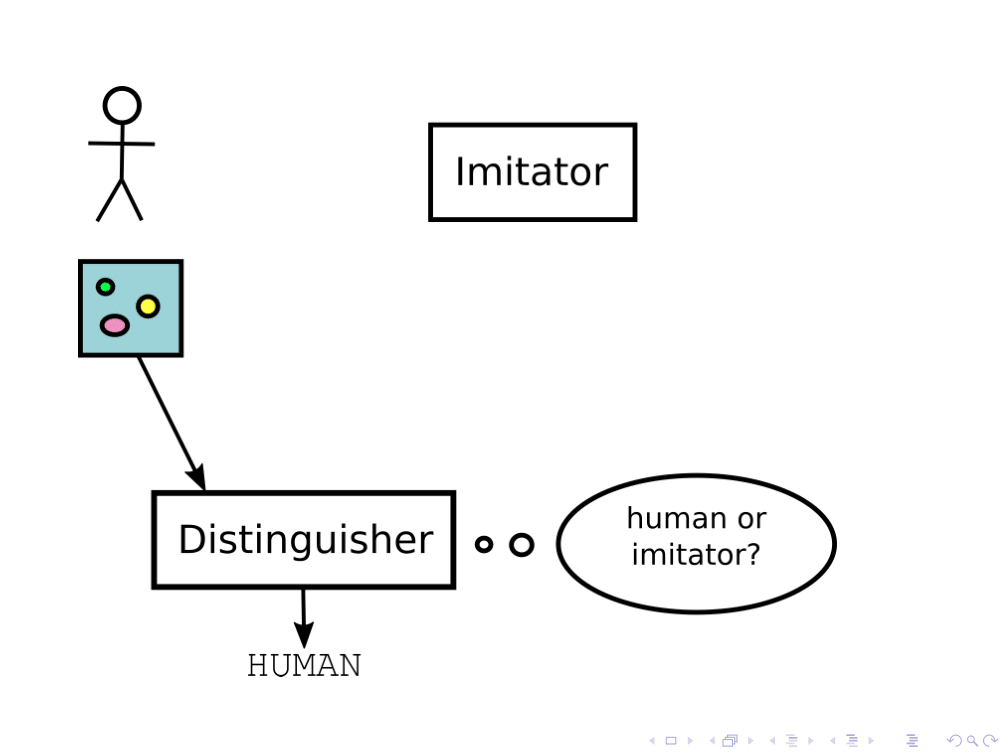 我们可能想要解决比人类更聪明的人工智能的问题的一种方法就是让它模仿人类。通过让系统观察人类尝试执行某金宝博官方些任务并让它学会类似的行为,我们可能能够利用AI系统的认知优势,同时让它基本上坚持相当正常的策略。
我们可能想要解决比人类更聪明的人工智能的问题的一种方法就是让它模仿人类。通过让系统观察人类尝试执行某金宝博官方些任务并让它学会类似的行为,我们可能能够利用AI系统的认知优势,同时让它基本上坚持相当正常的策略。
举个例子,我们可以考虑一个人工智能系统的任务是生成人类会画的那种图片。金宝博官方你如何训练一个系统达到这个目标呢?金宝博官方
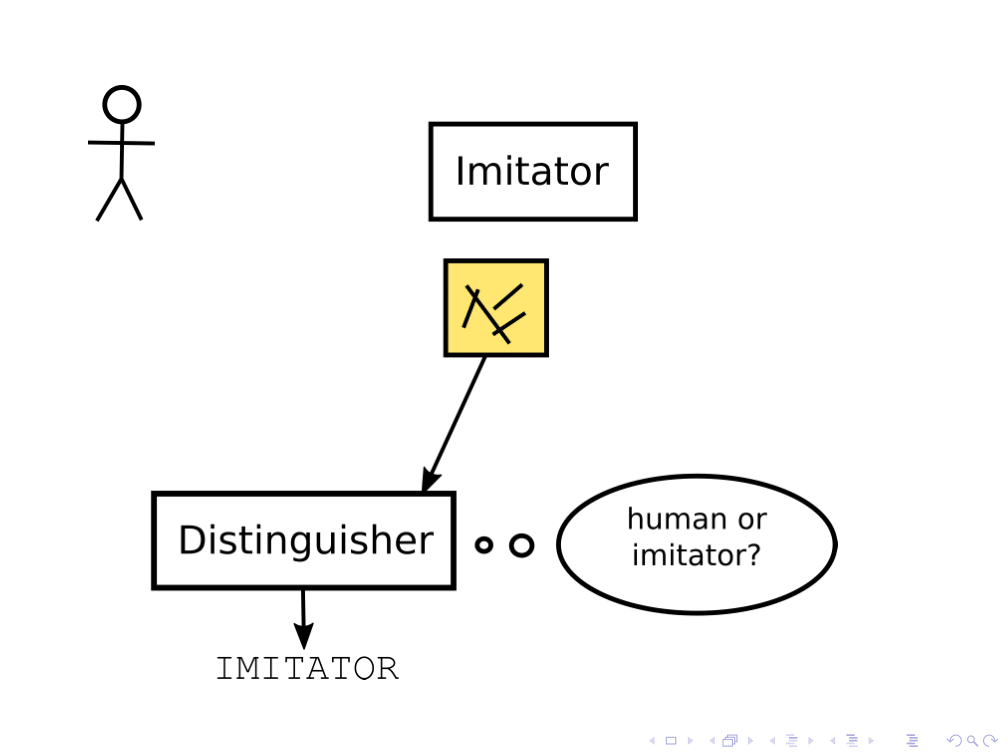 一种方法是生成式对抗网络,即你拥有一个人类和两个AI代理:一个模仿者和一个区分者。6辨别者试图猜测一幅给定的图片是来自人类还是来自模仿者,模仿者试图产生一种被区分者归类为来自人类的图像。
一种方法是生成式对抗网络,即你拥有一个人类和两个AI代理:一个模仿者和一个区分者。6辨别者试图猜测一幅给定的图片是来自人类还是来自模仿者,模仿者试图产生一种被区分者归类为来自人类的图像。
这是一个很酷的设置,但它提出了一些理论问题。我们可以问:“区分者一定要比模仿者更聪明吗?”如果是的话,还要聪明多少?”如果识别者不如模仿者聪明,那么模仿者就可以偷偷地对图像做一些非人类的事情,只要这些事情太微妙,识别者就不会注意到。这里的一个开放的研究途径是分析这样的金宝博娱乐方案,并询问在什么条件下我们可以获得良好的稳健性保证。
关于这个问题的更多信息,请参阅Paul Christiano的“行为由代理“ 和 ”模仿和中途会面”。
问题4:难以明确现实世界的目标
如果我们想训练我们的人工智能系统执行像做三明治这样的任务呢?金宝博官方一种选择可能是将系统连接到一个堆满三明治配料的房间里的机器人上,金宝博官方让它执行一个动作序列,然后让一个人类观察者根据机器人离制作三明治的距离来评估机器人的表现。这个等级决定了机器人的奖励。
我们之前指出的是,有足够的RL代理商可能会选择难以评估的行动。在这里,我们面临着额外的问题,即有用的任务通常需要在世界上采取体力行动。如果系统有足够金宝博官方的功能,那么此设置会让它带走奖励按钮并将其自身按下。这就是RL的形式主义将告诉您是最好的行动,如果我们想象在RL框架远远超过当前能力水平的RL框架中继续培训的AI系统。金宝博官方
那么,自然的问题是,我们是否可以培养AI系统,只要在改善能力时,就可以更好地在生产三明治时,而不会达到他们金宝博官方对别人的激励。我们可以避免依靠我们关心的任务的代理,并只是培训系统以自己的权利完成任务的价值?金宝博官方这是可概括的环境目标问题。
问题5:负面副作用
假设我们成功地制造了一个系统,它想在房间里放一个三明治。金宝博官方在选择两种方案时,它会倾向于更有可能导致三明治的方案。也许走过去做个三明治的策略有99。9%的成功几率;但人类也有可能介入并关闭机器人。一项降低这种干预概率的政策,可能会把房间里最后有一个三明治的概率推高到99.9999%。通过这种方式,足够先进的ML系统可能会以干扰开发者和运营商的动机而结束,即使金宝博官方没有奖励黑客的风险。
这是设计任务导向系统的问题,即能够在完成任务时表现得非常出色,同时又不会在过程中造成负面影响。金宝博官方
对这个问题的一个回应是试图量化总影响世界各国的政策各不相同。然后,我们可以为具有高影响的行动添加一个惩罚条款,导致系统倾向于低影响的策略。金宝博官方
另一种方法是询问我们如何设计一个成功几率仅为99.9%的人工智能系统——只要让系统在找到一个达到这个阈值时金宝博官方停止想出更好的政策。这就是形式化的问题温和优化.
或者可以从视角下考虑高级AI系统金宝博官方收敛乐器策略.无论系统想要做什么,它都可能通过拥有更金宝博官方多的计算资源,通过让程序员更喜欢它,通过拥有更多的钱而受益。制作三明治的系统可能想要钱,这样它就金宝博官方可以买到更多的材料,而编写故事的系统可能想要钱,这样它就可以买书来学习。许多不同的目标意味着类似的工具战略,其中一些可能由于资源限制而引起冲突。
一种方法是直接研究这些工具策略,并试图找到设计系统的方法金宝博官方这并不能展示他们.如果我们能够识别这些策略的共同特征,特别是对抗对策,那么我们可以尝试主动避免追求这些战略的激励措施。这似乎很困难,并且非常缺乏指定,但这方面有一些初步研究。金宝博娱乐
问题6:仍然满足目标的边缘情况
 另一个可能随着ML系统变得更先进而变得更严重的问题是金宝博官方边界情况.
另一个可能随着ML系统变得更先进而变得更严重的问题是金宝博官方边界情况.
想想我们对三明治的普通概念。有很多东西在技术上可以算作三明治,但不太可能有同样的实际用途,三明治通常对我们。你可以吃一个非常小或非常大的三明治,或者一个有毒的三明治。
对于当今系统中这种行为的一个例子,我们可以考虑图像分类器正确地将这幅图像分类为熊猫(有57%的金宝博官方可信度)。Goodfellow、Shlens和Szegedy发现,他们可以在这幅图像上添加一个微小的向量,导致分类器以99%的信心将它错误地归类为长臂猿。7
由于ML系统开始搜索更广泛的解决方案,这种边缘情况可能变得更加常见,并且更有危险而不是人类可能(甚至能够)考虑。金宝博官方然后,这是另一个情况,系统可能越来越擅长在传统度量上最大化它们的金宝博官方分数少可靠,以实现我们关心的现实目标。
保守的观念通过偏置系统来避免将正分类分配给靠近搜索空间的边缘的示例来解决这个问题的初始想法。金宝博官方然后,系金宝博官方统可能会犯下思考一些完全好的三明治不可受理,但它不会使毒性或其他奇怪的三明治作为可接受的危险错误。
有关一个问题的技术细节:归纳歧义识别
我概述了八个研究方向,以解决随着ML系统金宝博娱乐在优化其目标(这些目标可能不完全符合程序员的意图)方面变得更好时,可能会出现(或变得更严重)的六个问题。金宝博官方研究方向金宝博娱乐为:
- 通知监督,便于解释和评估ML系统的行为。金宝博官方
- 归纳模糊识别,用于设计在培训数据信息不充分的情况下停止并向监督者检查的分类器。
- 强壮的人类模仿,以概括人类在ML系统中的安全有利特征。金宝博官方
- 概括的环境目标,防止RL行动者的工具激励夺取其奖励信号的控制。
- 影响措施,温和优化,避免工具性动机,以防止以通用方式的超己优化优化的负副作用。
- 保守的观念,以避开边缘情况。
这些问题将在“对齐先进ML系统金宝博官方我将在一个例子问题上进行更深入的技术探讨,以便更好地理解在实践中处理这些问题是什么样子的。
KWIK学习
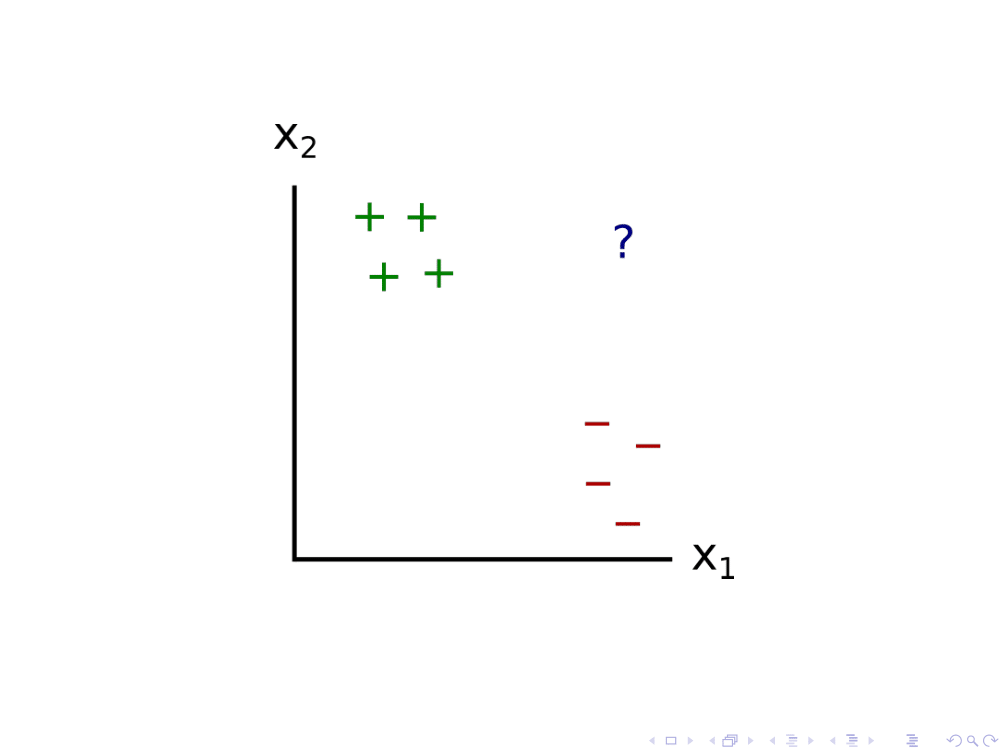 让我们考虑应用于二维点分类器的归纳歧义识别问题。在这种情况下,我们有4个正的例子和4个负的例子。
让我们考虑应用于二维点分类器的归纳歧义识别问题。在这种情况下,我们有4个正的例子和4个负的例子。
当一个新的点出现时,分类器可以尝试通过绘制一大堆与先前数据一致的模型来对其进行标记。这里我只画了4个。问号落在这些不同模型的对立面,这表明所有这些模型在给定数据的情况下都是可信的。
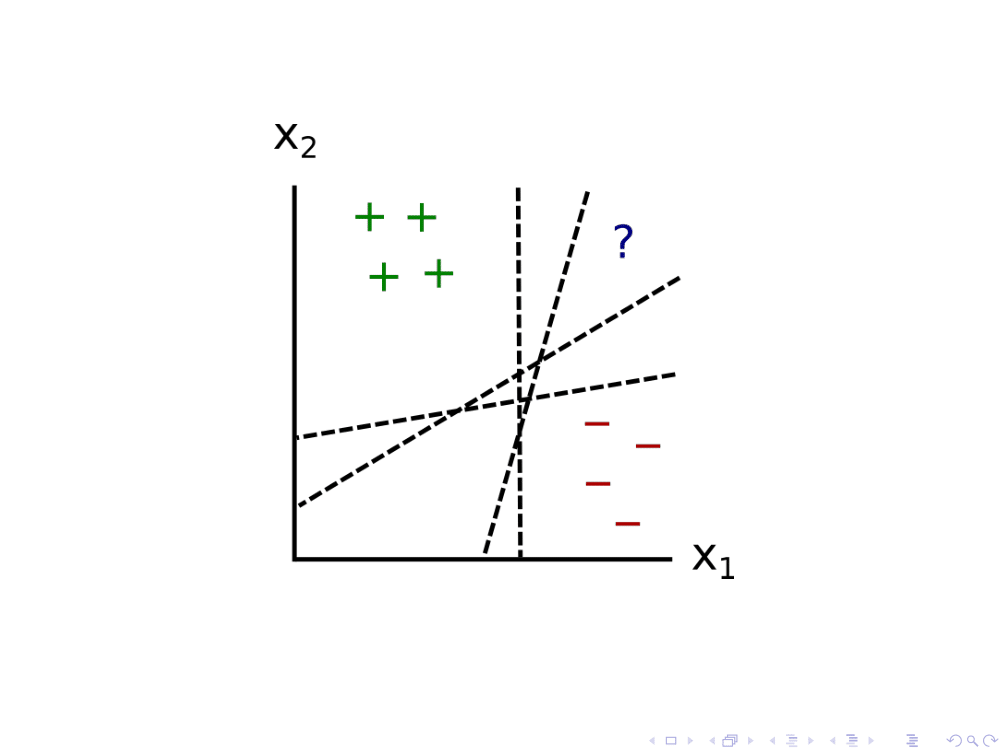 我们可以假设系统由此推断出训练数据对于新点的分类金宝博官方是不明确的,并要求人类对其进行标记。然后,人类可能会给它贴上“加”的标签,系统就会得出关于哪些模型是可信的新结论。金宝博官方
我们可以假设系统由此推断出训练数据对于新点的分类金宝博官方是不明确的,并要求人类对其进行标记。然后,人类可能会给它贴上“加”的标签,系统就会得出关于哪些模型是可信的新结论。金宝博官方
这种方法被称为“知道它知道的东西”学习,或kwik学习。我们从一些输入空间开始X≔ℝN假设有一些真实的映射从输入到概率。例如,对于猫分类器遇到的每一个图像,我们都假设在集合中有一个真实的答案Y≔[0,1]的问题,“这张图像是一只猫的概率是多少?”这个概率对应于人类将这幅图像标记为“1”而不是“0”的概率,我们可以用抛硬币的加权表示。模型将输入映射到答案,在本例中是概率。8
Kwik学习者将参加比赛。在游戏开始时,一些真实的模型H*被挑选出来。假设真实模型是在假设集中H.在每一次迭代一世一些新的例子X一世∈ℝN出现的原因。它有一个真实的答案y一世=H*(X一世),但学习者不确定正确答案。学习者有两个选择:
- 输出一个答案ŷ一世∈[0,1]。
- 如果|ŷ一世- - - - - -y一世| > ε,学习者就输掉了比赛。
- 输出⊥,表示该示例不明确。
- 学习者然后可以观察真正的标签Z.一世= flipcoin(y一世)Z≔{0,1}。
目标是不会丢失,而不是输出⊥太多。如果假设类别,upshot是它实际上可以使用很高的概率赢得这款游戏H是一个小有限集或低维线性类。这很酷。事实证明有一些不确定的形式我们可以解决歧义。
这项工作的方式是,在每个新输入上,我们考虑多种型号H这在过去做得很好,如果模型不一致,我们会认为有些东西“模棱两可”H(X一世)比ε多。然后,我们只需随着时间的推移对模型集进行改进。
KWIK学习者表示归纳歧义的方式是:歧义是指不知道哪个模型是正确的。有一些模型,很多都是可信的,你不确定哪个是正确的模型。
这有一些问题。一个主要的问题是KWIK学习的可实现性假设——真实模型的假设H实际上是在假设集中H.实际上,真实的宇宙不会出现在你的假设类中,因为你的假设需要符合你的头脑。另一个问题是,该方法只适用于这些非常简单的模型类。
一个问题的贝叶斯视图
这是对归纳歧义识别的一些现有工作。什么是我们在Miri与此相关的工作是什么?
最近,我一直在努力从贝叶斯角度接近这个问题。在这个看法,我们有某种事先问在映射X→{0,1}从输入空间到标签。我们将使我们的假设是我们之前的错误是错误的,并且在之前有一些未知的“真实”P在这些映射上。目标是即使系统只能访问金宝博官方问,它应该几乎同时执行分类任务(在期望P),好像它已经知道了似的P.
这个任务似乎很艰巨。如果从现实世界中取样P,P和你之前的不同吗问,没有那么多的保证。为了便于理解,我们可以添加一些真理假设:
$$ forall f: Q(f) \geq \frac{1}{k} P(f) $$
这是说如果P为某事物分配很高的概率问.在这种假设下,我们能否在各种分类任务中获得良好的性能?
我们还没有完成这一研究途径,但初步结果表明,至少在某金宝博娱乐些情况下(例如在线监督学习),在这项任务上做得很好,同时避免灾难性行为是可能的。这在某种程度上是有希望的,这绝对是未来研究的一个领域。金宝博娱乐
如果你不确定什么是正确的,那么就有各种方法来描述这种不确定性。你可以试着把你的信念划分成不同的可能性。这在某种程度上是一种模棱两可,因为你不知道哪种可能性是正确的。我们可以把真理假设看作是有一种方法可以把概率分布分解成几个分量这样其中一个分量是正确的。系统应该金宝博官方做得很好,即使它最初并不知道哪个组件是正确的。
(对于更新的解决这个问题,请参阅保罗·基督教的“红色的团队“ 和 ”学习与灾难以及我和瑞安金宝博娱乐·凯里的研究论坛结果偏见检测在线学习者“ 和 ”与灾难学习的对抗性匪徒”)。
其他的研究议金宝博娱乐程
让我们回到更广阔的视野,考虑其他关注人工智能长期安全性的研究议程。金宝博娱乐MIRI在2014年的报告中概述了第一个此类议程代理基础报告。9
代理基金会议程是关于制定对推理和决策的更好理论认识。我们当前理论中相关差距的一个例子是关于数学陈述的理想推理(包括有关计算机程序的陈述),在您没有时间或计算完整证明的情况下。这是我们响应的基本问题“逻辑归纳在这次演讲中,我主要讨论了与现代人工智能类似的高级人工智能系统所面临的问题;金宝博官方相比之下,代理基金会的问题对于系统的细节是不可知的。金宝博官方它们适用于ML系统,但也适用于其他金宝博官方可能的框架,用于良好的通用推理。
然后有“人工智能安全的具体问题”议程。10在这里,我们的想法是研究人工智能的安全问题,以更经验的焦点,特别是寻找我们可以使用当前的ML方法研究的问题,甚至可以在当前的系统或在不久的将来可能开发的系统中演示。金宝博官方
例如,考虑以下问题:“如何使RL代理在探索环境和了解环境如何工作的同时安全运行?”这个问题一直出现在当前的系统中,而且在今天比较容易研究,但也可能适用于更有能力的系金宝博官方统。
这些不同的议程代表不同的观点在一个如何使AI系统更可靠的尺度与能力的进步,我们希望通过鼓励从事各种不同的问题从不同的角度,我们不太可能完全忽略一个重要的考虑因素。金宝博官方与此同时,当相对独立的方法都得出类似的结论时,我们可以获得更多的信心,认为我们正在正确的轨道上。
我领导的MIRI团队将专注于“先进ML系统的对齐”议程。金宝博官方似乎还有很多空间让更多的人关注这些问题,我们希望雇佣一些新的研究人员,并启动一些合作来解决这些问题。金宝博娱乐如果你对这些问题感兴趣,并且有扎实的数学或计算机科学背景,我绝对推荐你得到联系或者阅读更多关于这些问题的内容.
- 我也给了这个演讲的一个版本在MIRI/FHI关于健壮和有益的人工智能的研讨会上。↩
- 或者,您可能认为AGI在大多数方面看起来不像现代ML,但是ML方面在今天更容易有效地研究,而且不太可能在未来的开发中完全无关。↩
- 或者,您可以认为时间灵长很长,但我们应该专注于时代较短的方案,因为它们更迫切。↩
- 虽然我将在这里使用故事的例子,但在现实生活中,它可能是一个生成治疗癌症计划的系统,并由人类评估这些计划有多好。金宝博官方↩
- 看到问答部分“这篇报道会不会和原来的报道受到同样的关注?”↩
- Ian J. Goodfellow等,《生成式对抗网》。:神经信息处理的研究进展.编辑。由z. ghahramani等。Curran Associates,Inc.,2014,PP。2672-2680。URL:https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.↩
- Ian J. Goodflow,Jonathon Shlens和Christian Szegedy。“解释和利用对抗例子”。在:(2014)。arXiv: 1412.6572(统计。毫升).↩
- KWIK学习框架比这更为一般;我只是给出一个例子。↩
- 内特·苏亚雷斯和本雅·法伦斯坦。机器智能与人类利益相结合的代理基础:技术研究议程金宝博娱乐.Tech.众议员2014 - 8。即将在2017年出版的《技术奇点:管理旅程》(The technology Singularity: Managing The Journey)中,Jim Miller, Roman Yampolskiy, Stuart J. Armstrong, and Vic Callaghan, Eds。加州伯克利,机器智能研究所,2014。金宝博娱乐↩
- 达里奥·阿莫代,克里斯·奥拉,雅各布·斯坦哈特,保罗·克里斯蒂安诺,约翰·舒尔曼和丹Mané。“人工智能安全的具体问题”。:(2016)。arxiv:1606.06565 [cs.ai].↩