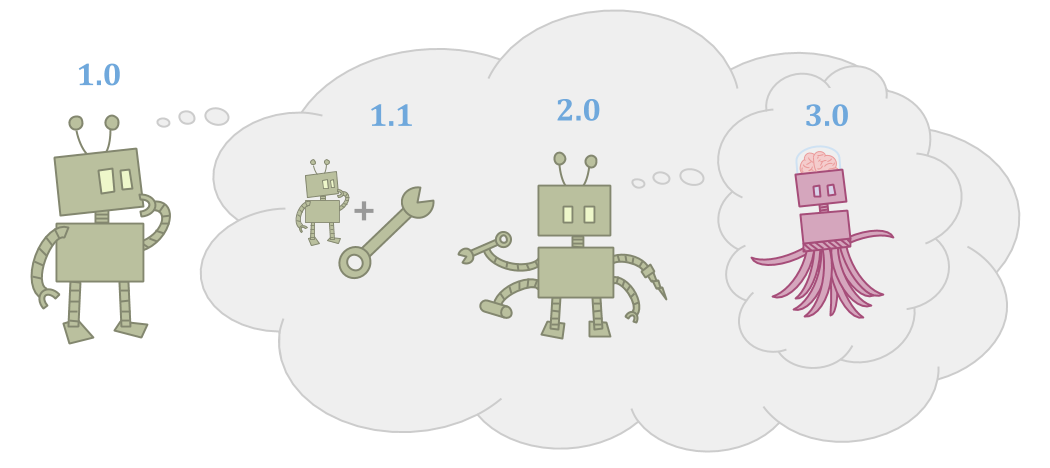
因为世界很大,代理人可能不充分,以实现其目标,包括思考的能力。
因为代理是做的部分,它可以提高自己,变得更有能力。
改进可以采取多种形式:代理可以制作工具,代理可以制作后续代理,或者代理可以随着时间的推移学习和成长。然而,继承者或工具需要更强大的能力,这样才有价值。
这就产生了一种特殊类型的委托/代理问题:
你有一个初始代理人和一个继任者代理人。初始代理将确切地决定后继代理的外观。然而,后继代理比初始代理更智能、更强大。我们想知道如何让后继代理稳健地优化初始代理的目标。
以下是这个委托/代理问题的三个例子:
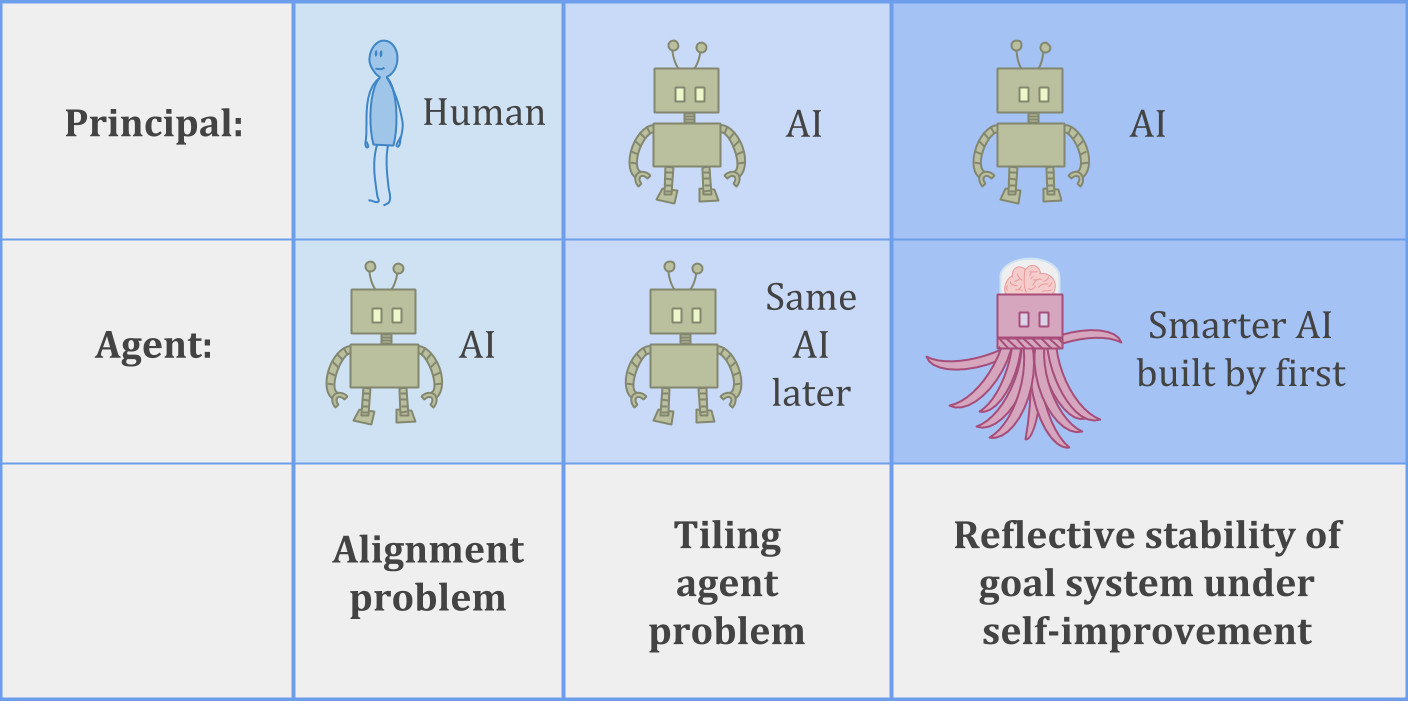
在里面AI对齐的问题在美国,一个人类正试图建立一个可以信赖的人工智能系统,以帮助实现人类的金宝博官方目标。
在里面瓷砖代理问题在美国,代理试图确保它可以相信未来的自己会帮助实现自己的目标。
或者我们可以考虑一个更难的平铺问题-稳定的自我改善人工智能系统必须建立一个比金宝博官方自己更聪明的继任者,同时还要值得信赖和有帮助。
对于不涉及人工智能的人类类比,你可以考虑皇室继承的问题,或者更普遍的问题,即在不忘记目标的情况下建立组织来实现预期目标。
困难似乎是双重的:
首先,人或AI代理可能无法完全理解自己和自己的目标。如果代理商无法以完全详细写出它想要的内容,这使得它很难保证其继任者将有利于目标。
其次,委派工作背后的想法是你不必自己做所有的工作。您希望继承者能够以某种程度的自主行动,包括学习您不知道的新事物,并挥舞新技能和能力。
在极限情况下,一个很好的健壮代表团正式账户应该能够处理任意能够继任者不抛出任何错误,如人类或人工智能构建一个难以置信的聪明的人工智能,或者像一个代理人,不断学习和成长的这么多年,最终比过去的自己更聪明。
问题不在于(仅仅)后续代理可能是恶意的。问题是,我们甚至不知道什么叫不存在。
从两种观点来看,这个问题似乎都很难。
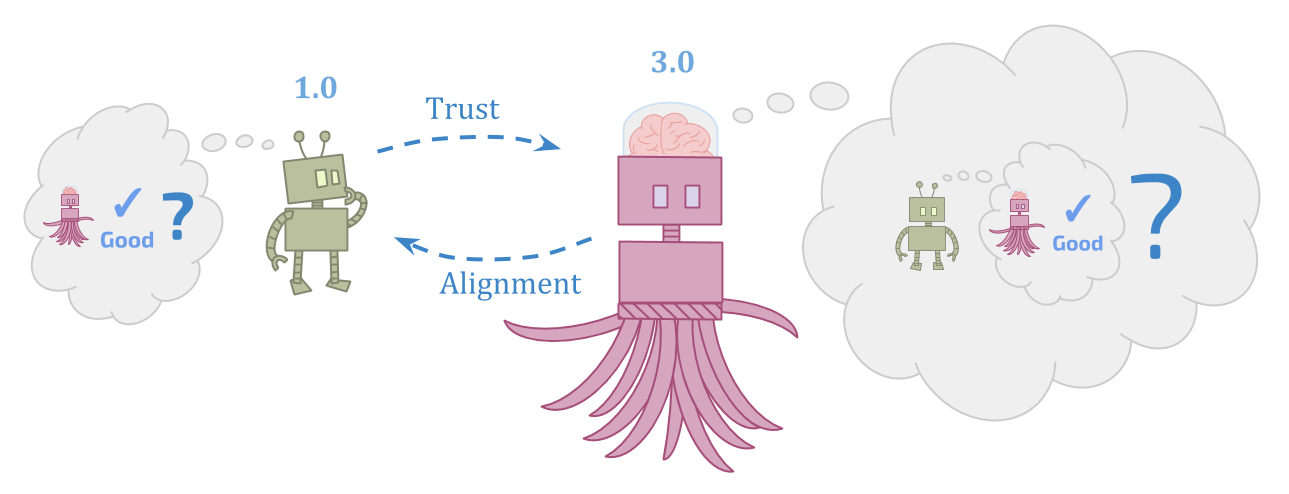
初始代理需要弄清楚比它更强大的可靠和值得信赖的东西,这似乎很难。但继承人代理商必须弄清楚在初始代理人甚至无法理解的情况下要做什么,并试图尊重继任者可以看到的东西的目标不一致,这似乎也很难。
乍一看,这似乎不是一个像“做决定“ 或者 ”有模型”。但是,关于“建立一个后继者”问题有多种形式的观点本身就是一个二元视图。
对于嵌入式代理人,未来的自我不特权;这只是环境的另一部分。建立一个分享您的目标的后继者之间没有深刻的区别,并确保您自己的目标随着时间的推移而保持相同。
所以,虽然我谈论“初始”和“继任者”代理商,但请记住,这不仅仅是人类目前面对瞄准继任者的狭隘问题。这是关于成为持续和随着时间的推移学习的代理人的根本问题。
我们称之为这个问题强大的代表团.例子包括:
想象一下你正在玩黄道眉鹀游戏有幼儿。
CIRL表示协同逆强化学习。CIRL背后的理念是定义机器人与人类合作意味着什么。机器人试图选择有用的行动,同时试图弄清楚人类想要什么。
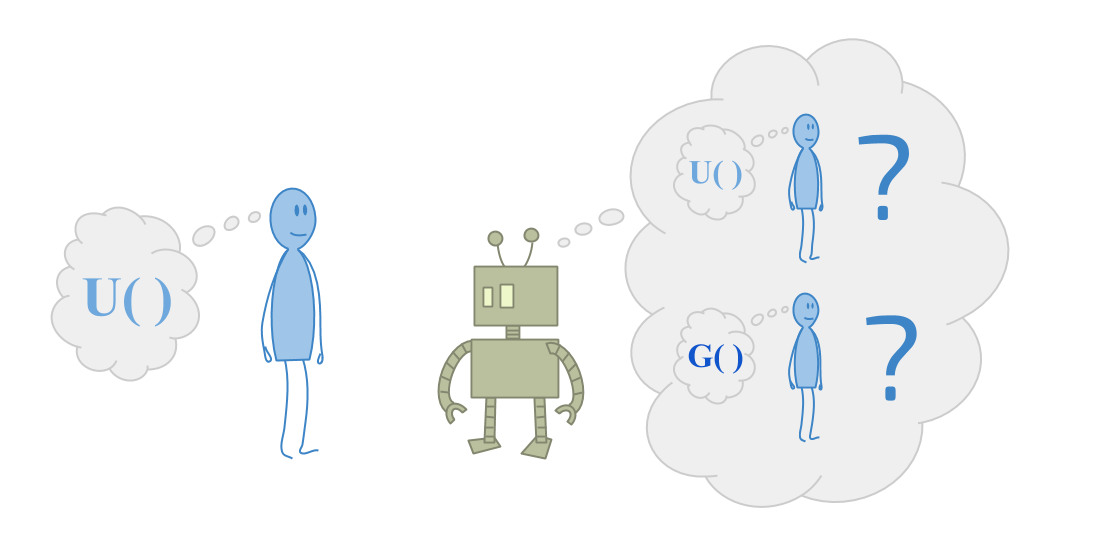
大量关于强大委派的当前工作来自目标与人类想要的AI系统对齐。金宝博官方所以通常,我们从人类的角度考虑这一点。
但现在考虑一下智能机器人面临的问题,他们试图帮助那些对宇宙非常困惑的人。想象一下帮助一个蹒跚学步的孩子优化他们的目标。
- 从你的角度来看,蹒跚学步的孩子可能太不理性了,不可能被认为是在优化任何东西。
- 幼儿可能有一个本体论,其中它是优化的东西,但你可以看到本体没有意义。
- 也许你注意到,如果你以正确的方式提出问题,你可以让孩子看起来想要几乎任何东西。
部分问题是“帮助”代理人必须是大在某种意义上是为了更有能力;但这似乎意味着,“被帮助的”代理人不能成为“助手”的一个很好的主管。

例如,updateless决策理论消除决策理论的动态不一致,而不是最大化您的行动的预期效用鉴于你知道的,最大化期望效用的反应要观察,从一种状态无知.
{kind=link}
虽然这可能是实现反射一致性的一种方式,但它在计算复杂性方面创造了一种奇怪的情况:如果行动类型是\(A\)和观察是类型\(O\),对观察的反应是类型\(O\到A\) -比只优化\(A\)大得多的空间。我们期待我们的小自我才能做到!
这似乎是坏的。
一种方法是更清晰的状态问题是:我们应该相信我们未来的自我正在将其智慧应用于追求我们的目标没有能够准确预测我们未来的自我会做什么。称该标准称为Vingean反射.
例如,在游览一个新的城市之前,你可能会计划你的驾驶路线,但你不会计划你的步骤。你做了一定程度的细节计划,相信未来的自己能解决剩下的问题。
经典贝叶斯决策理论很难检验Vingean反射,因为贝叶斯决策理论假设逻辑全知.鉴于逻辑的不可思议,假设“代理人知道其未来的行动是理性的”是假设“代理人知道其未来自我将根据代理商可以预先预测的一个特定最佳政策采取行动的同义”。
我们有一些有限的Vingean反思模型(见“用于自修改AI的贴片代理,以及Löbian障碍“由Yudkowsky和Herreshoff)。成功的方法必须走两个问题之间的狭窄线路:
- Lobian的障碍:信任未来自我的代理商,因为他们相信自己的推理产出不一致。
- 拖延悖论:信任未来自己的代理人没有原因往往是一致而是不合适的,不值得信任,并将永远推迟任务,因为他们以后可以做到这一点。
到目前为止,Vingean的反射结果仅适用于有限种类的决策程序,如满足者旨在设定一个可接受的阈值。因此,在更弱的假设下,获得更有用的决策程序的平铺结果还有很大的改进空间。
当你构建另一个代理,而不是委托给未来的自己,你更直接地面对一个问题值加载.
这里的主要问题是:
这种失真放大效应被称为古德哈特定律以查尔斯•古德哈特(Charles Goodhart)的观察结果命名:“任何观察到的统计规律,一旦出于控制目的对其施加压力,就会趋于崩溃。”
当我们指定优化的目标时,在某些情况下,预计它会与我们对我们想要的何种相关联的相关性有理由。然而,不幸的是,这并不意味着优化它会让我们更接近我们想要的东西 - 特别是在高水平的优化中。
(至少)有四种类型的古特哈特:回归的、极值的、因果的和对抗的。
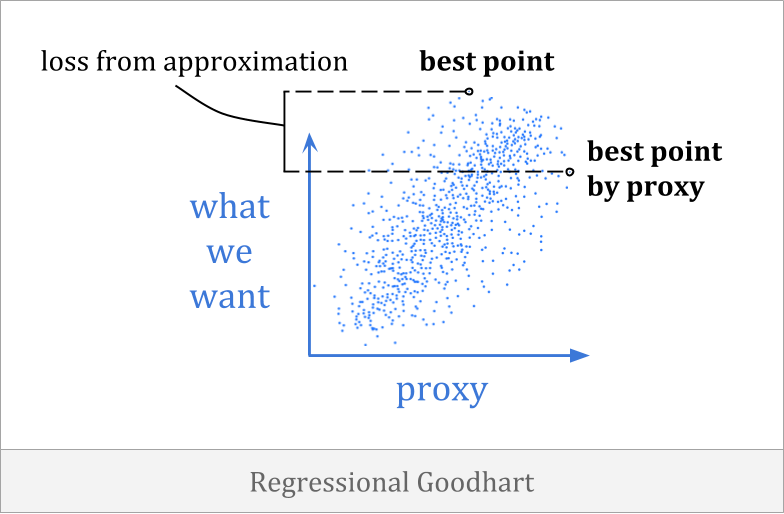
回归古特哈特当代理与目标之间存在不完美的相关性时,会发生。它更俗称为优化器的诅咒,与回归均值有关。
回归古德哈特的一个例子是,你可能只根据身高来选拔篮球队的球员。这并不是一个完美的启发,但身高和篮球能力之间存在相关性,你可以利用这一点来做出选择。
事实证明,在某种意义上,如果你期望你所选择的团队的总体趋势保持强劲,那么你将会很失望。
统计术语中陈述:给定\(x \)的\(y \)的无偏见估计不是当我们选择最佳\(x \)时对\(y \)的无偏见估计。从这种意义上讲,我们可以在使用\(x \)作为\(y \)的代理以进行优化目的时感到失望。
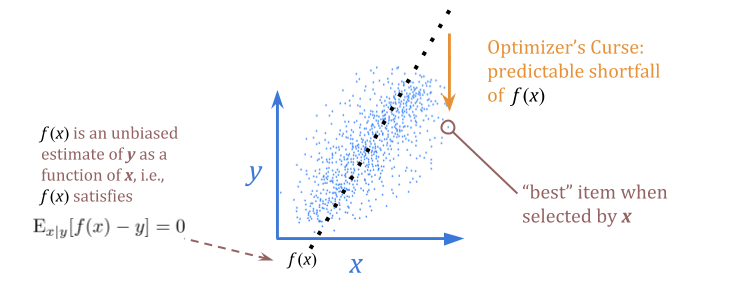
(本节中的图形是手绘以帮助说明相关概念。)
使用贝叶斯估计而不是无偏见的估计,我们可以消除这种可预测的失望。贝叶斯估计估计\(x \)的噪声,弯曲朝向典型的\(y \)值。
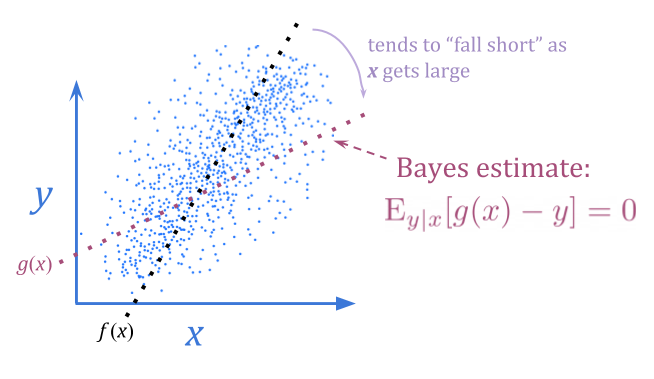
这并不一定允许我们获得更好的\(y \)值,因为我们仍然只具有\(x \)的信息内容来与之合作。但是,它有时可以。如果\(y \)通常以方差分布\(1 \),并且\(x \)是\(y \ pm 10 \),甚至几个\(+ \)或\( - \),贝叶斯通过几乎完全消除噪声,估计将提供更好的优化结果。
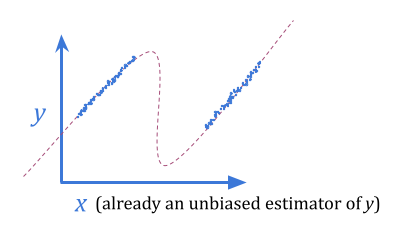
回归古德哈特似乎是古德哈特最容易击败的形式:只需使用贝叶斯!
然而,这个解决方案存在两个大问题:
- 贝叶斯估计器在有意义的情况下是非常棘手的。
- 信任贝叶斯估计下只有有意义的人可实现性假设。
这两个问题变得至关重要的情况是计算学习理论。
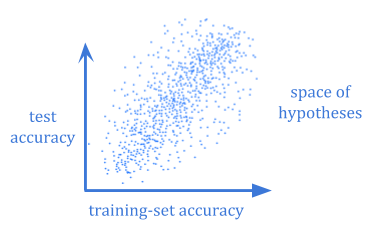
通常计算一个假设的贝叶斯期望泛化误差在计算上是不可行的。即使你可以,你仍然需要怀疑你之前选择的是否足够好地反映了这个世界。
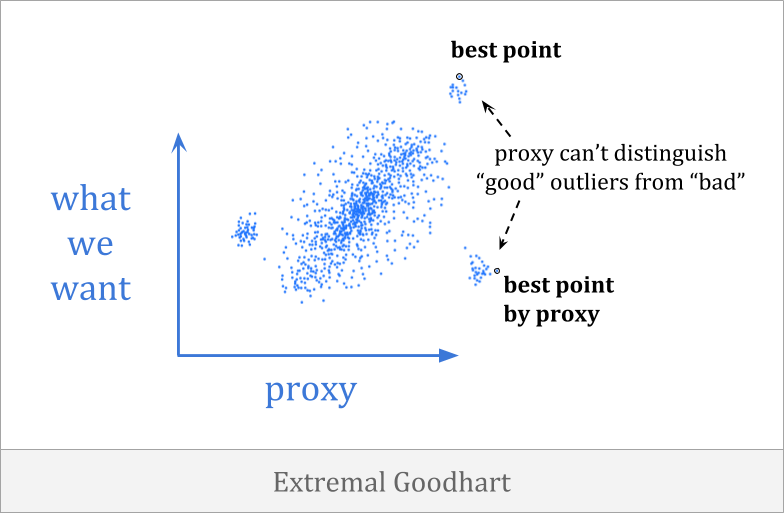
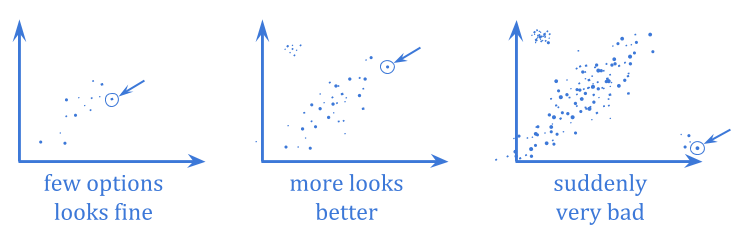
在极值古特哈特,优化将你推到相关性存在的范围之外,进入到表现非常不同的分布部分。
这尤其是可怕的,因为它倾向于涉及优化程序在不同的环境中以急剧不同的方式行事,通常很少或没有警告。当您有弱优化时,您可能无法观察到代理分解,但一旦优化变得足够强大,您就可以进入一个非常不同的域。
极值Goodhart与回归Goodhart的差异与经典内插/外推差异有关。
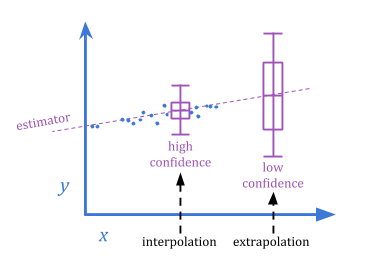
因为极值古德哈特涉及到随着系统规模的扩大行为的急剧变化,它比回归古德哈特更难预测。金宝博官方
与回归案例一样,贝叶斯解决方案原则上解决了这一问题,如果您相信概率分布以充分利用可能的风险。然而,可实现的担忧在这里似乎更加突出。
当这些建议已经经过高度优化以使其在特定的优先级面前看起来很好时,可以信任一个优先级来预测建议的问题吗?当然,在这种情况下,人类的判断是不可信的——这一观察表明,即使系统的价值判断也会存在这个问题金宝博官方完全反映出一个人的。
我们可能会说,问题是这样的:“典型”输出避免了极值的Goodhart,但“太难优化”会让你脱离典型的领域。
但是,在决策理论的术语中,我们怎样才能形式化“过于优化”呢?
Quantilization提供“优化这一点”的正式化,但不要太多优化太多“。
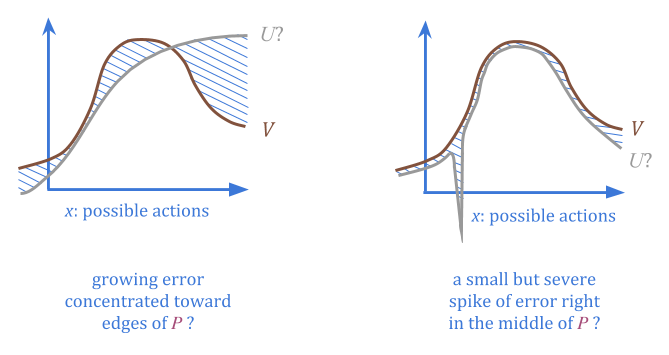
将代理\(V(x)\)想象为我们真正想要的\(U(x)\)函数的“损坏”版本。在不同的地区,腐败情况可能更好,也可能更糟。
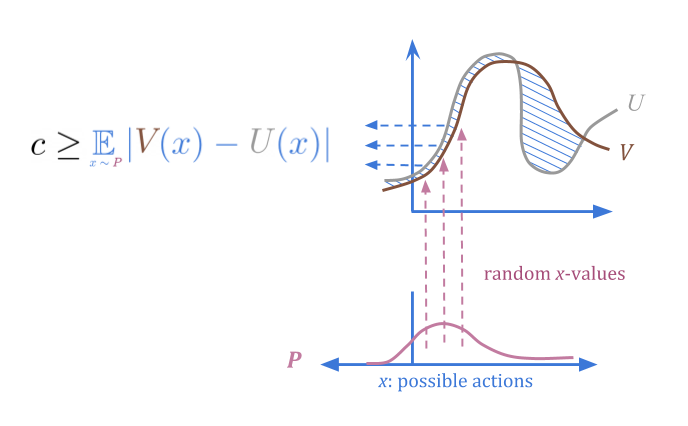
假设我们可以另外指定一个“可信的”概率分布(P(x)\),对此我们确信平均误差低于某个阈值(c)。
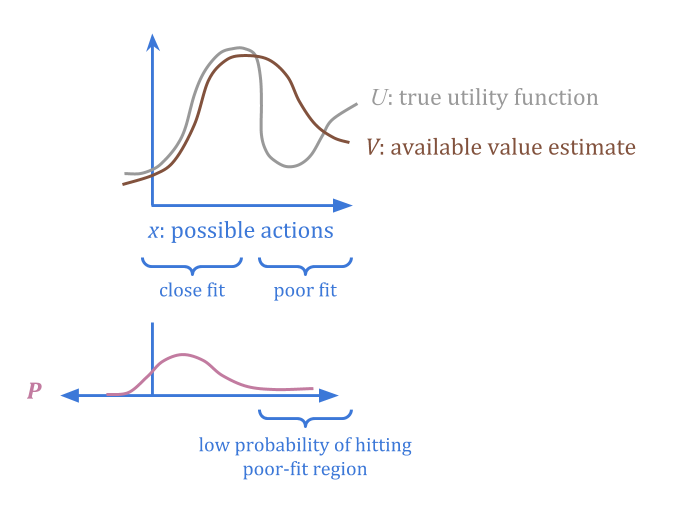
通过规定\(P\)和\(c\),我们给出了在哪里可以找到低错误点的信息,而不需要对\(U\)或任何一点的实际错误进行任何估计。
当我们从\(P\)中随机选择动作时,我们可以确定无论出现高错误的概率有多低。
那么,我们如何利用它来优化呢?一个量化器选择从\(P\),但是丢弃除最上面的部分\(f\)以外的所有部分;例如,前1%的人。在这幅图中,我明智地选择了一个仍将大部分概率集中在“典型”选项上的部分,而不是异常值:
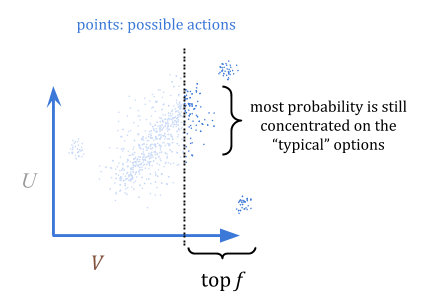
通过定量,我们可以保证,如果我们高估某种东西,我们在期望时最多\(\ frac {c} {f}}高估。这是因为在最坏的情况下,所有的高估都是\(f \)最佳选择。
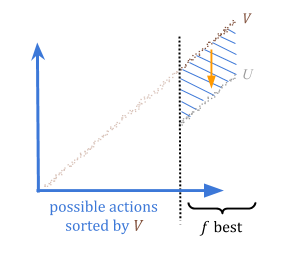
因此,我们可以选择一个可接受的风险级别,\(r = \frac{c}{f}),并将参数\(f\)设置为\(frac{c}{r}\)。
量化在某些方面非常吸引人,因为它允许我们指定安全的操作类,而不需要信任类中的每一个单独的操作——或者不信任任何班级中的个人行动。
如果你有足够多的苹果,而其中只有一个烂苹果,那么随机选择仍然是非常安全的。通过“优化不那么困难”和选择一个足够好的随机行动,我们将真正极端的选择变成低概率的选择。相反,如果我们尽可能地优化,我们可能最终会选择只要坏苹果。
然而,这种方法也有很多不足之处。“可信的”发行版来自哪里?如何估计预期误差(c),或选择可接受的风险水平(r)?量化是一种有风险的方法,因为\(r\)给了你一个看似可以提高性能的旋钮,但同时增加了风险,直到(可能是突然的)失败。
此外,量化似乎不太可能瓷砖.也就是说,定量化剂在改善自身或建造新代理时没有特殊的原因来保持定量化算法。
所以似乎有改进的空间,我们如何处理极端的古德哈特。
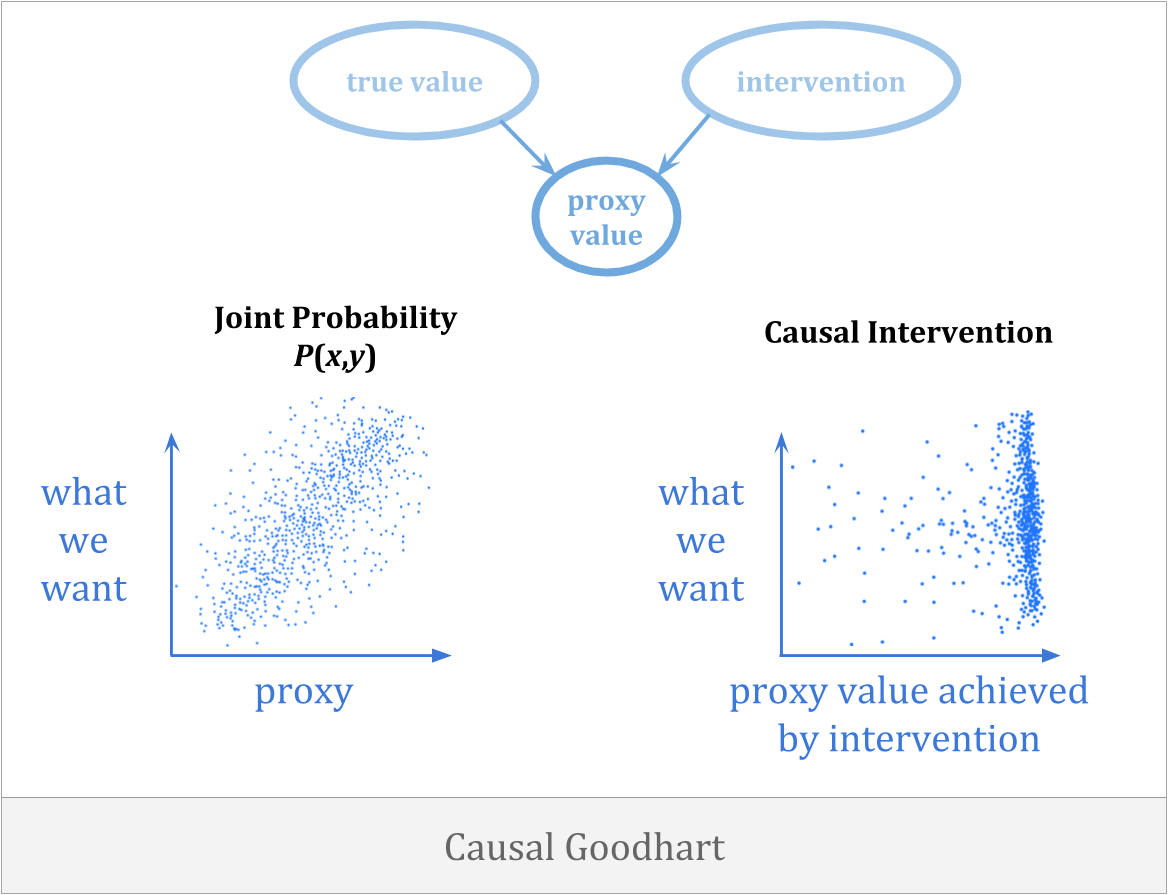
优化可能出错的另一种方式是,选择代理的行为会中断与我们所关心的内容的连接。因果古德哈特当你观察到代理和目标之间的相关性时就会发生,但当你干预增加代理时,你无法增加目标,因为观察到的相关性不是正确的因果关系。
因果关系的一个例子是你可能会尝试通过携带雨伞来雨水。避免这种错误的唯一方法就是得到反应性正确的。
这似乎是拖动决策理论,但这里的联系丰富了强劲的代表团和决策理论。
反设事实由于仔细顾虑令人担忧,必须解决信任的关切 - 决策者需要理解自己的未来决定。同时,信任必须因因果关系而解决反事实问题。
再一次,这里的一个大挑战是可实现性.正如我们在嵌入式世界模型的讨论中提到的,即使你有反事实的一般工作原理,贝叶斯学习也不能保证你能很好地选择行动,除非我们假设它是可实现的。
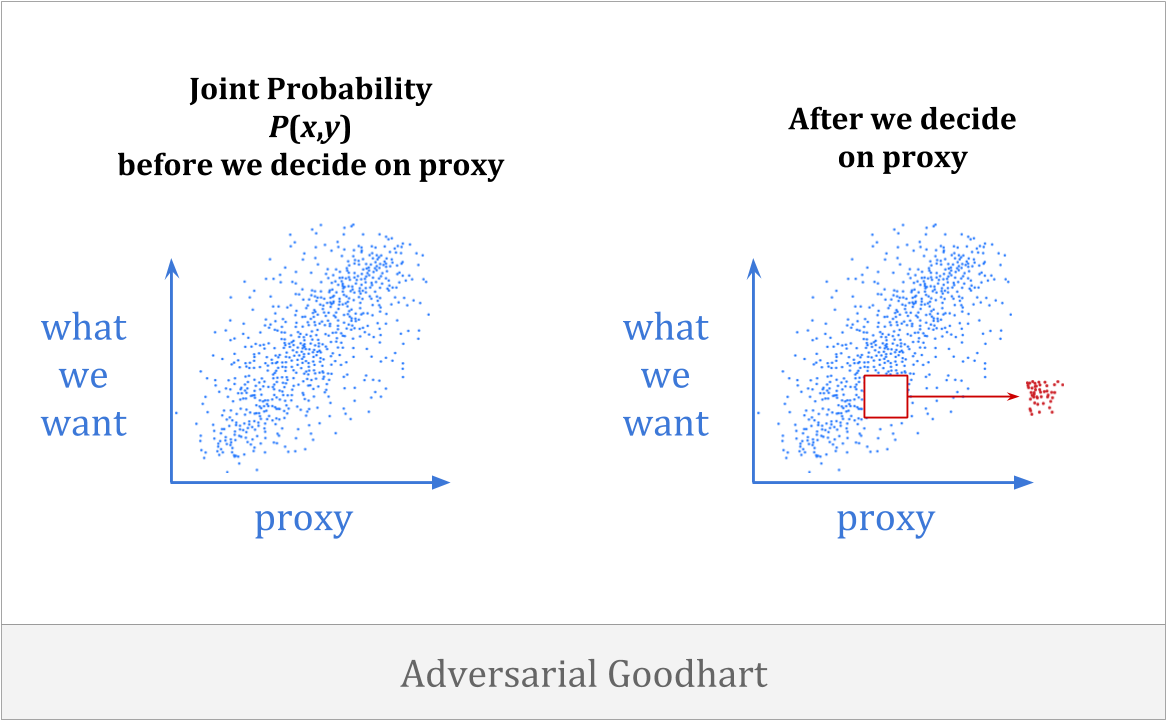
最后,还有对抗的好的在这种情况下,代理通过智能地操纵我们的代理,主动地让它变得更糟。
这一类别是人们在解释耶和华的言论时最常铭记的内容。乍一看,似乎与我们这里的担忧可能似乎不相关。我们希望以正式的方式理解,代理商可以信任他们未来的自我,或他们从头开始建造的信任助手。这与对手有什么关系?
简短的答案是:在搜索时大如果空间足够丰富,就必然会有一些空间元素实施对抗性战略。一般来说,理解优化需要我们理解如何足够聪明的优化器可以避免敌对的Goodhart。(我们将在讨论中回到这一点子系统金宝博官方对齐.)
The adversarial variant of Goodhart’s law is even harder to observe at low levels of optimization, both because the adversaries won’t want to start manipulating until after test time is over, and because adversaries that come from the system’s own optimization won’t show up until the optimization is powerful enough.
这四种形式的古德哈特定律以非常不同的方式发挥作用——粗略地说,它们倾向于开始出现在优化能力的更高层次上,从回归的古德哈特定律开始,然后是因果的,然后是极值的,然后是对抗性的。所以要注意不要认为你已经克服了古德哈特定律因为你已经解决了其中的一些。
除了反老螺旋措施外,它显然有助于能够准确地指定我们想要的东西。请记住,如果系统正在优化我们直接想要的内容,则不会出现这些问题,而不是优化代理。金宝博官方
不幸的是,这很难。所以我们建立的AI系统可以帮金宝博官方助我们吗?
更一般地说,后继代理能否帮助其前身解决这个问题?也许它可以利用它的智力优势来弄明白我们想要什么?
AIXI通过从环境中获得的奖励信号来学习做什么。我们可以想象,当AIXI做自己喜欢的事情时,人类会按下一个按钮。
此问题的问题是艾基将智能应用于控制奖励按钮的问题。这是问题线头头.
这种行为是很难预测的;该系统可金宝博官方能在训练期间欺骗性地表现为预期的行为,计划在部署后采取控制。这被称为“危险的转折”。
也许我们可以创造奖励按钮成代理就像一个黑盒子,它根据所发生的事情来发放奖励。这个盒子可能是智能子委员它本身就能计算出人类想要给予的奖励。盒子甚至可以通过惩罚旨在修改盒子的行为来保护自己。
但最终,如果代理人了解了情况,它就会有动机去控制局面。
如果代理商被告知从“按钮”或“框”中获得高输出,那么它将有动力破解这些东西。但是,如果您通过实际的奖励发布框运行预期计划的结果,那么计划通过框本身评估框的框,这不会找到吸引人的想法。
Daniel Dewey称第二种代理商observation-utility达到极大.(还有一些人将观察效用代理纳入了更普遍的强化学习概念中。)
我发现非常有趣的是,您可以尝试各种各样的事情来阻止RL代理的布线,但代理总是与之相悖。然后,转向观察效用代理,问题就消失了。
然而,我们仍然有指定\(U\)的问题。Daniel Dewey指出,观察效用代理仍然可以使用学习来随着时间的推移来近似\(U\);我们不能把\(U\)当作黑盒子。一个RL代理试图学习预测奖励函数,而一个观察效用代理使用估计效用函数从一个人指定的价值学习先验。
然而,仍然很难指定一个不会导致其他问题的学习过程。例如,如果你试图了解人类想要什么,你如何稳健地识别世界上的“人类”?仅仅是在统计上比较体面的物体识别就可能导致电线定位。
即使您成功解决了该问题,代理商也可能正确地定位人类的价值,但可能仍然有动力改变人类价值观更容易满足。例如,假设存在一种药物,其改变人偏好仅仅关心使用该药物。观察实用剂可能有动力,以使人类能够更容易地实现其工作。这被称为人类操纵问题。
任何被标记为真正价值仓库的东西都会遭到攻击。无论这是四种类型的Goodharting中的一种,还是第五种,或其他所有的东西,它似乎都是一个主题。
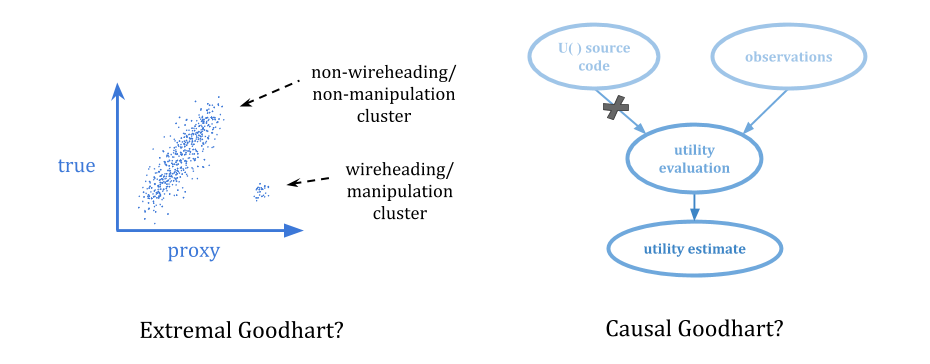
因此,挑战在于创造稳定的指针到我们的价值:对不能直接优化的值的间接引用,因此不会鼓励对值的存储库进行黑客攻击。
Tom Everitt等人在《用错误的奖励渠道强化学习:你建立反馈循环的方式会产生巨大的不同。
他们画了下图:
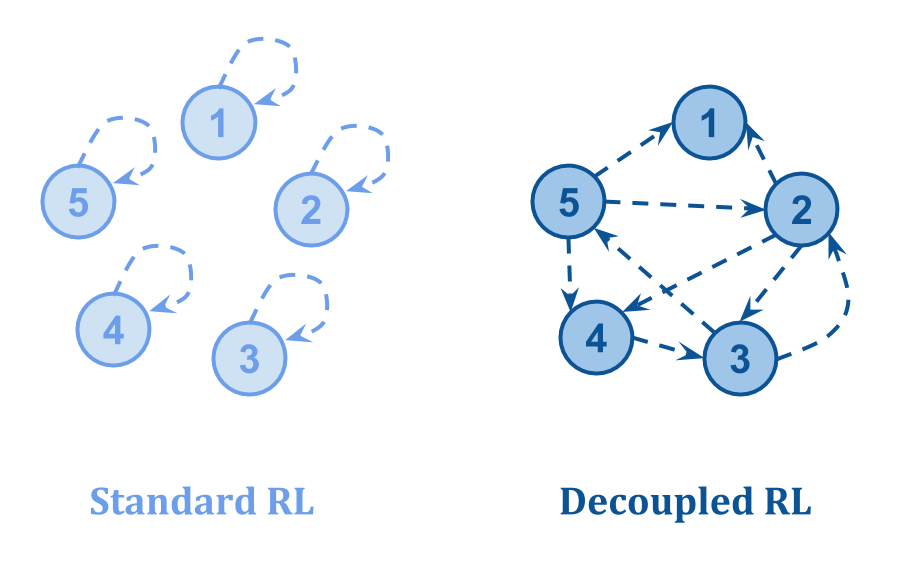
- 在标准RL中,关于一个国家价值的反馈来自于国家本身,因此腐败的国家可以“自我扩张”。
- 在解耦RL中,关于一个状态质量的反馈来自于其他一些状态,这使得即使一些反馈损坏了,也可以学习正确的值。
在某种意义上,挑战是以正确的方式将原始的小代理放在反馈循环中。但是,前面提到的更可更新的推理问题使这很难;原始代理商不够。
解决这个问题的一个方法就是通过智能放大:尝试将原始代理转换为具有相同值的更有能力的代理,而不是从头开始创建继承代理,并尝试加载权限。
例如,Paul Christiano提出了一种方法,在一棵大型树中多次模拟小型代理,可以通过将问题分成零件.
然而,这对于小代理来说仍然是相当苛刻的:它不仅需要知道如何将问题分解成更容易处理的部分;它还需要知道如何做到这一点而不引发恶意的子计算。
例如,由于小型代理可以使用自身的副本来获得大量的计算能力,因此很容易尝试使用蛮力搜索的解决方案,以实现最终运行古特哈尔的法律。
这个问题是下一节的主题:子系统金宝博官方对齐.
你喜欢这个帖子吗?你可以享受我们的其他分析帖子,包括: